
数据库系统复习
任课老师:黄忠东
知识点梳理
DML
select得到的结果通过distinct关键字来去重union all可以保留并集中的重复元组- 注意
case与update组合使用时,分段更新
聚合函数&NULL
除了 count之外的聚合函数, 会忽略集合属性上有 null的元组, 而 count则会计算包括空值在内的元组个数.
Special case: 如果所有的聚合属性都是空值:
count: 返回0;- 其他聚合函数: 返回 null.
lateral
外层的查询可以直接使用内部查询的关系名, 但是内部的子查询无法向外直接使用其重命名的关系名.
然而, 如果在子查询的前面声明关键字 lateral则可以实现:
1 | SELECT name, salary, avg_salary |
嵌套查询顺序
from ; where; group by ; having; select; distinct; order by
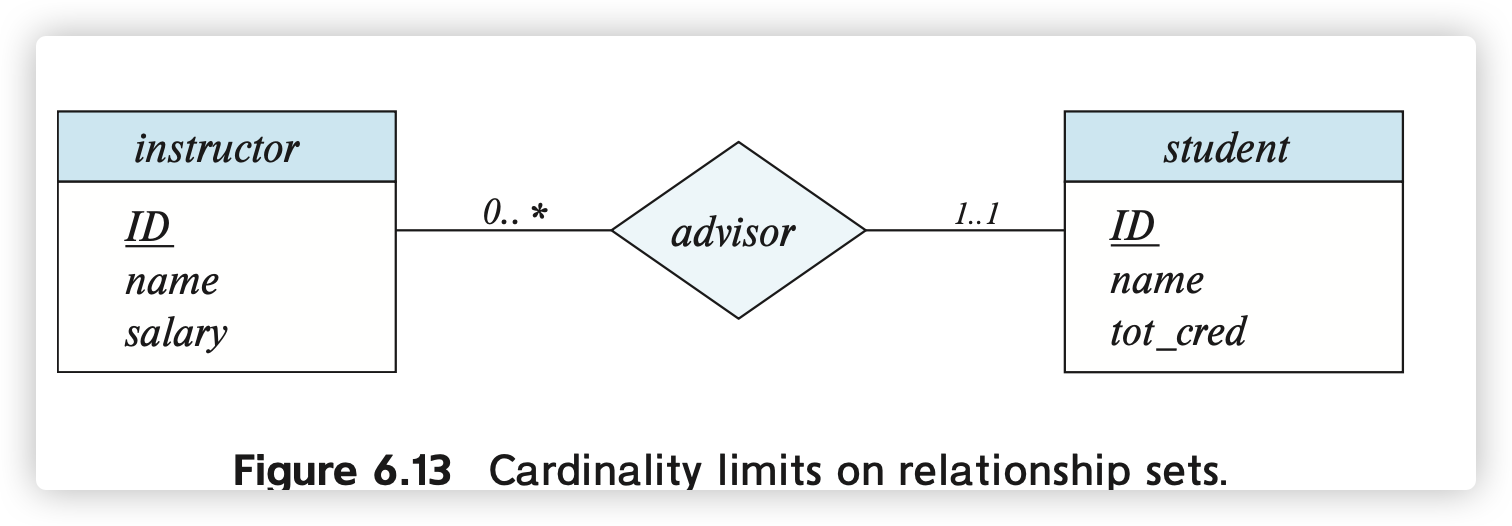
映射基数约束
采取 l...h的形式来表示复杂的约束关系:
0..*表示最少参与0次, 最多没有限制, 可见 ..对多的关系, 部分参与;1..1表示恰好参与1次, 表示一对..的关系, 完全参与
比如下面的实际上是many-to-one的关系:
ER模型和范式
从ER模型得到schema
从ER模型得到schema的核心规则:
- 关系类型:
- 1:1 :在参与关系的实体类型中,选择一个schema增加一个FK,指向另一个实体对应的schema的PK,不需要额外建模;
- 1:N: 在多端对应的schema中,增加1端对应的PK作为FK。此时,关系也蕴含在这个外键的约束关系中,不需要额外建模;
- M:N: 此时,我们需要将关系建模为一个新的schema——将参与关系的实体类型的主键作为外键,然后加上关系本身的属性,组成为schema的属性
- 弱实体类型:强实体的PK + 弱实体自身的分辨符 = 对应schema的主键,然后补充弱实体的剩余属性
- 多值属性:需要为多值属性构建一个新的schema
- 将对应的实体的PK和多值属性自身作为schema的PK
属性集闭包
注意,属性的闭包包括自身的属性集
作用:
- 判断是否为主键:如果闭包包含了关系中的所有属性,那么就是~
- 验证函数依赖是否成立
- 计算整个关系模式的闭包
: 计算每一个属性的闭包
正则覆盖
- 目标:简化给出的函数依赖
- 尝试化简属性A时,如果去除的是
中的: - 左侧:判断去除之后左侧剩余属性的闭包是否包含了右侧属性
- 右侧:判断此时的左侧属性闭包中是否含有去除的属性
- 我们可以进一步用公式来讲解上述的分析:
- 判断
中的属性A是否多余: - 计算
是否包含了
- 计算
- 判断
中的属性A是否多余: - 根据
的依赖关系,计算 - 如果对应的属性闭包包括了A,那么就可以去除
- 根据
- 判断

一个简单的例子来说明如何推导:

NOTICE:
- 实际情况下,可能比较难推导,需要更多的经验和灵感)
- 虽然我们要求左侧的属性唯一,但是在推导的过程中,可能尝试将类似于
先拆解为两条,然后判断其中的某条属性是否多余;最后将左侧属性合并
范式的验证
- BCNF:
- 如果F中没有违背BCNF原则的函数依赖,那么F的闭包中也没有
- 3NF:
- 注意,属性A可以来自不同的CK集合
- 只需要对已有的FD进行判断
存储结构
似乎不是经常考,了解概念
文件结构
- 面向列的存储可以在现代CPU中实现向量处理
定长与变长的记录
如果是定长记录,为了避免删除记录时调整结构的较大时间成本,可以为维护一个空表,将删除之后的空间通过链表的方式连接,之后插入的时候,首先插入到空表中,如果没有空余的位置,再插入到文件的末尾
如果记录是变长的,在定长和变长之间存在一个空位图:
位数 = 变长记录的个数
某个记录为空时 ==> 对应的bit为 1
定长的信息包含:
- 变长属性的定长属性信息(开始的偏移量+长度)
- 定长属性的值


B+树相关
索引的block大小
假设指针和search-key的大小分别是a,b 那么block的扇出n ( fan-out rate )就是:
注意最左侧存在一个单独的指针,然后是一系列的键值对;
扇出也就是B+树的阶数
children的关系
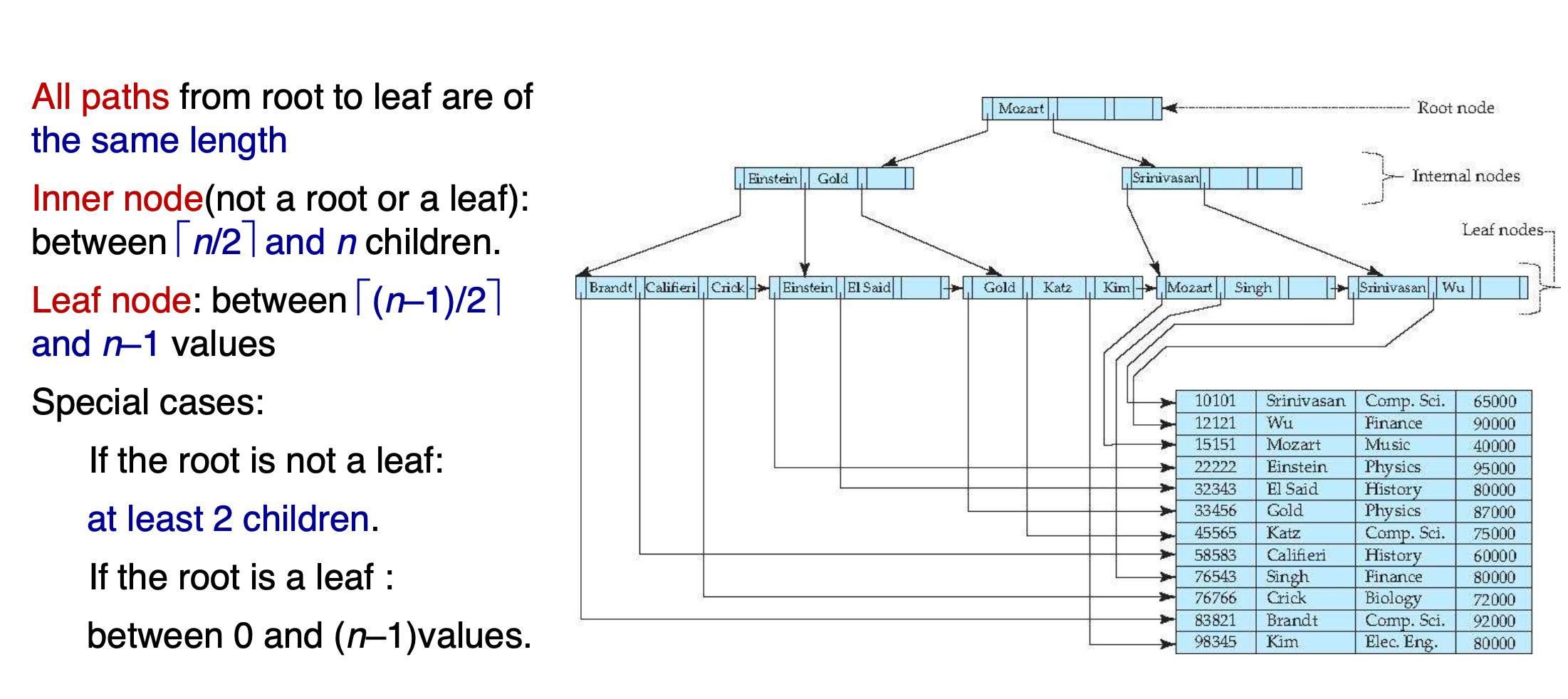
此处的
n就是之前计算得到的扇出;对于内部节点,最小值的估计是孩子而非关键字的个数!关键字key的个数是孩子数(指针)- 1
注意叶子节点根据索引值指向对应物理地址的记录,所以是n-1个孩子
叶子节点的最右侧的指针用于串联叶子节点的链表
非叶子节点类似于多级、稀疏索引。
高度的估计

高度最大估计如上所示;当叶子节点都满时,有最小高度
.
操作相关
删除:
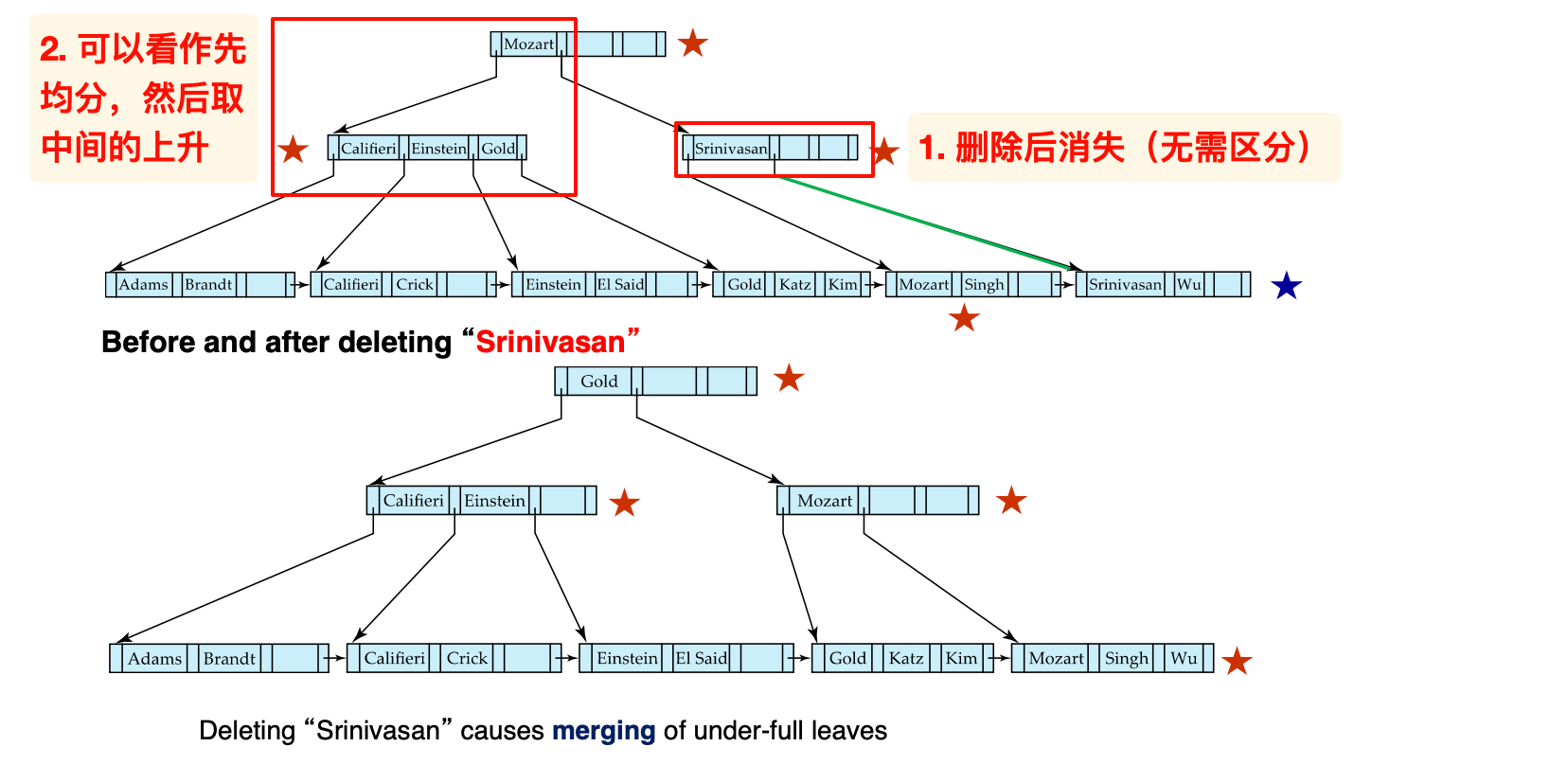
计算高度

根节点最少有2个子节点
B+树的范围查找:
- 如果是查找 <= x, 直接从第一个叶子节点开始按照链表遍历;
- 反之,从根节点开始寻找第一个满足条件的叶子节点,然后遍历到底
如果B+树的索引是字符串等变长的,可以采取前缀的方式来压缩索引项的大小,从而增大扇出n
bottom-up
- 如果记录已经存在,可以从叶子节点开始自底向上构造(首先排序)
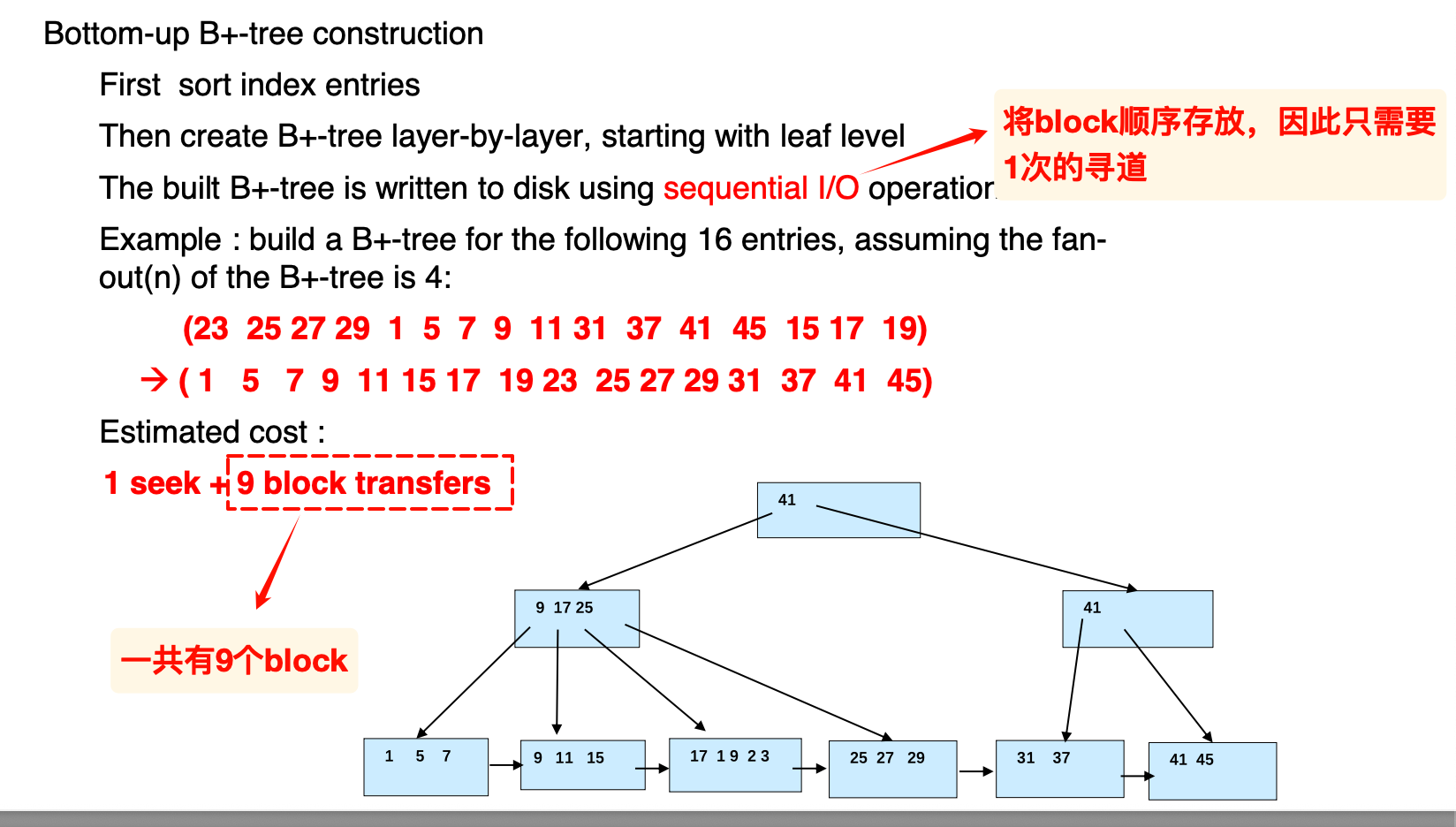
这种技术也用在了LSM的的构建上–当底层的L满了的时候,将其融合并自底向上构建
- 如果要批量插入,也可以先排序然后一起插入,可以有效减少访问的block数量
TODO:分析成本的估计
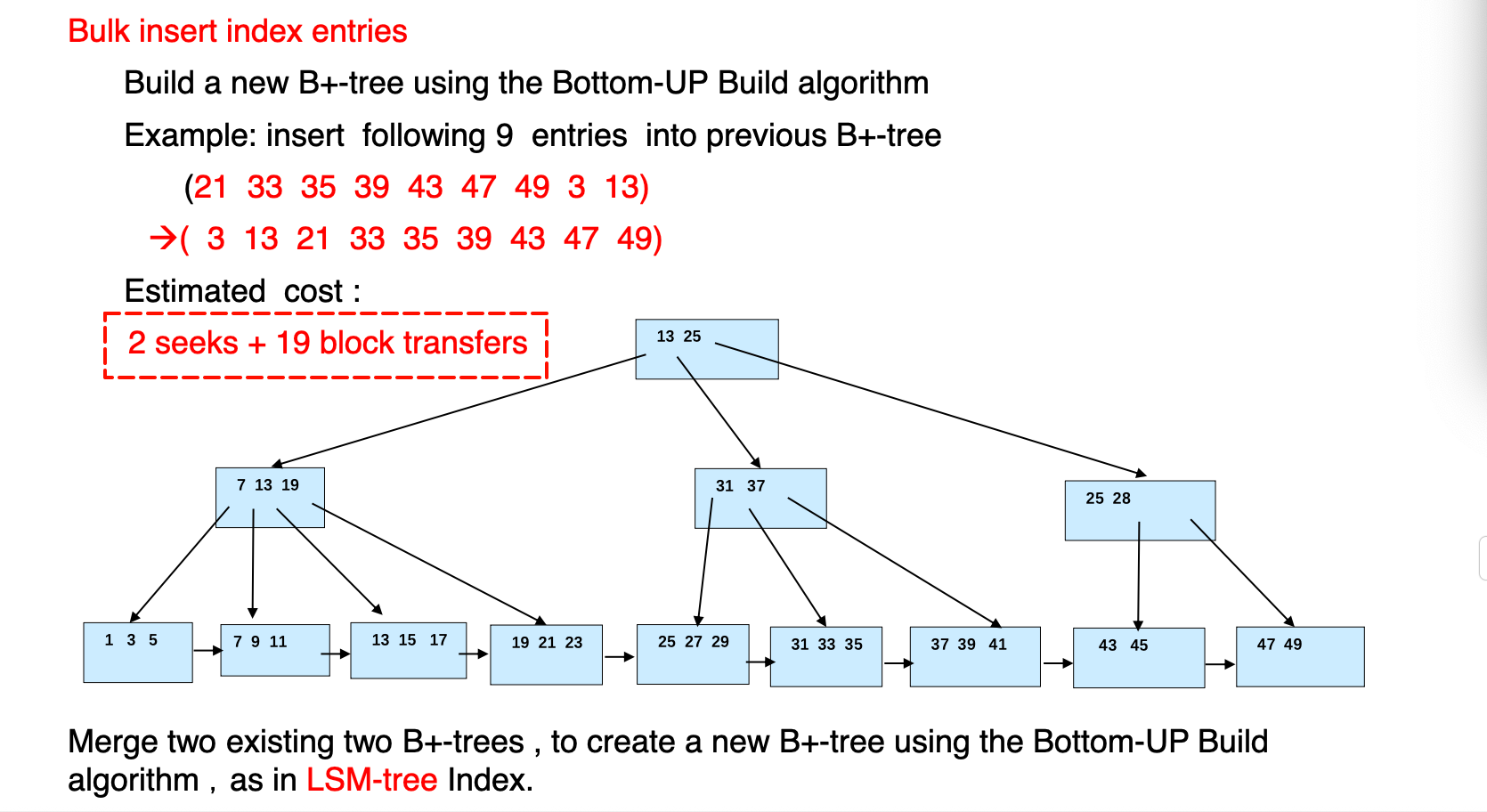
其他结构
LSM
- 将对数据的修改增量保存在内存中,达到一定的限制后批量写入磁盘,提升了写性能;
- 但是因此降低了一定的读性能
Buffer Tree
为节点增加内部的缓冲区:

- 插入: 如果缓冲区有空闲, 优先插入缓冲区中;
- 如果发生了节点的分裂, 注意同时管理缓冲区的转移;
- 缓冲区内部也是有序的.
- 查询: 需要在缓冲区中进一步查找
Bitmap
将Record标号, 然后为每个属性都建立一个 bitmap, 0表示对应的位置不是当前的属性, 1 表示符合当前属性.
- bitmap使得两个属性通过
and操作就找到对应的record.
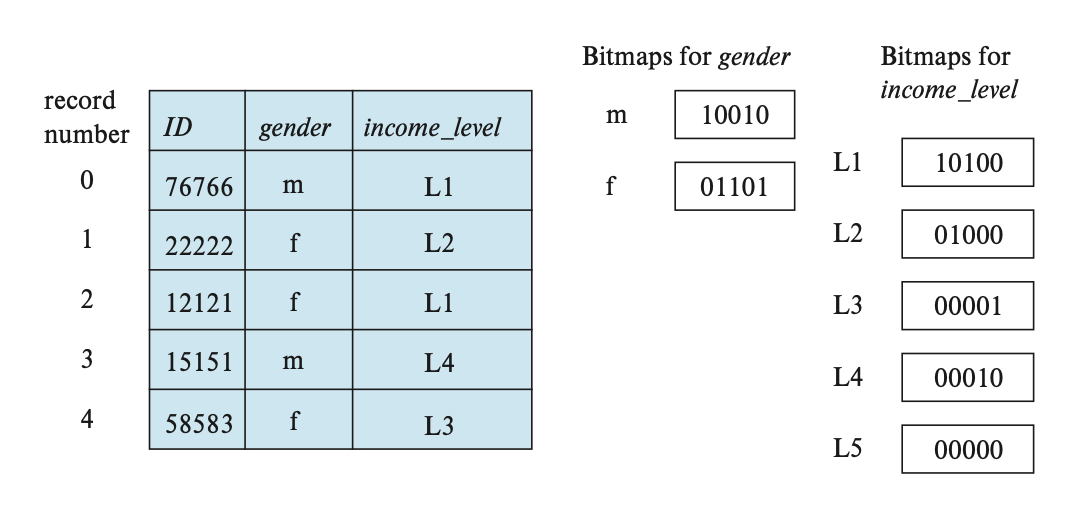
Index
- 顺序索引分为了稠密和稀疏两类,后者只能用于顺序文件,因为只有部分的search-key存在索引
- 如果搜索键没有重复的,那么稠密的顺序索引就包含了所有的搜索键的index;否则对于每一个搜索键,我们只需要一个开始的index,然后可以线性搜索得到
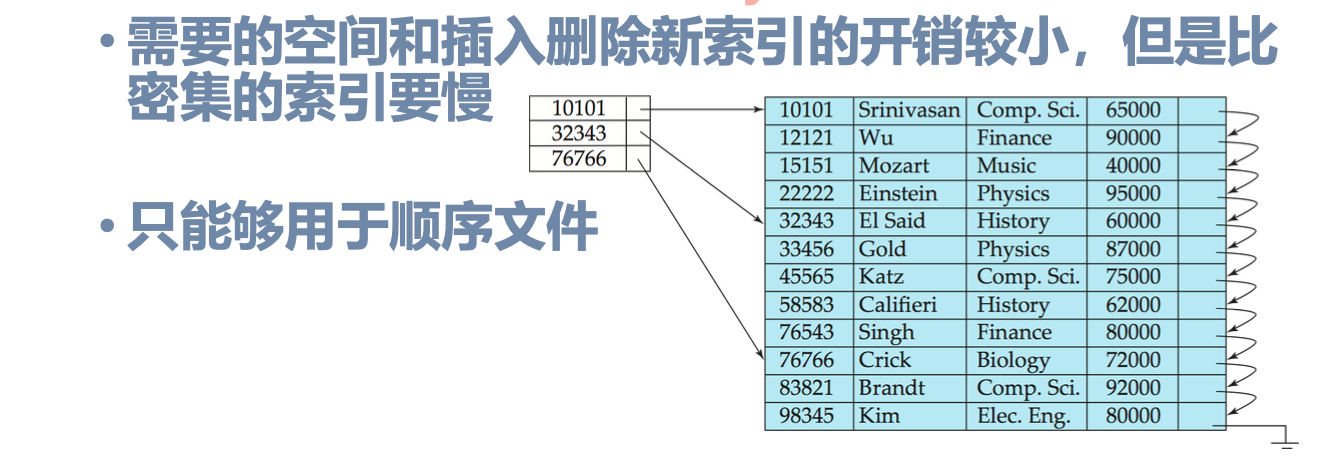
辅助索引
i.e. secondary key, 与primary-key(顺序)有所区别
当数据文件中的记录顺序和索引文件中的索引项的顺序不一致时:
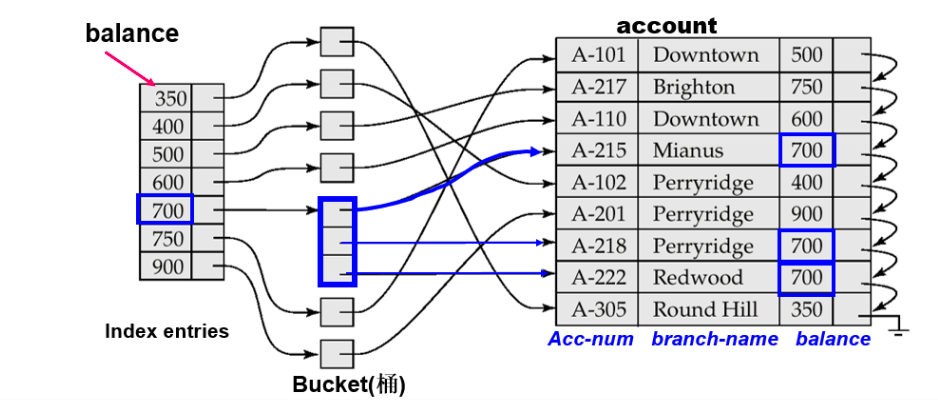
可以看到,辅助索引首先指向了一个bucket,bucket中存在二级索引
散列索引
选择索引,利用哈希函数计算K到B的映射,哈希值相同的索引项放在了一个bucket中
overflow chaining:如果某个bucket内部的项太多了,系统将分配一个~,用于存储额外的索引项(bucket本身也是一个链表)
为了减少上述桶溢出发生的概率,我们可以如此设置桶的数量
: 其中,分子和分母分别表示记录总数和每个桶的记录数量;d称为fudge factor,通常设置为0.2
Query Processing
- 整体思想: 先选择、再投影、最后连接和输出
成本估计:

Join-cost
嵌套循环
| join方式 | 块传输次数 | 寻道次数 | 备注 |
|---|---|---|---|
| Nested-Loop | |||
| Block Nested-Loop | s的block顺序存储,对于每个 |
||
| Index Nested-Loop | TODO | 条件:inner在连接属性上具有index |
在最好的情况下,嵌套和块嵌套的循环,内存可以装下两个关系,因此块传输次数为block的个数,寻道次数均为2
由于上述的计算是基于每次都读取外层关系1个block,我们可以继续改进上述的方法,让其每次读取M-2个block,留下2个block分别用于读取s的block和输出所用的空间
其中
为内存大小的block块数;每次读取r中一连串的block之后,读取s的block,并将s的record逐个与前者的记录比较
此时,块嵌套的块传输次数和寻道次数分别为:
merge join
- 要求关系按照连接属性有序排列,否则优先sort
Hash join
- 利用哈希函数,将连接属性具有相同哈希值的元组放在一个集合/划分
- 对两个关系分别计算哈希值并划分后,我们只需要考虑对应划分对
, - 之后,我们在上述的每个划分对,使用索引嵌套循环连接:
- 为inner关系build一个哈希索引,从outer关系中probe查找对应的元组
- 分别称r,s为探测输入和构建输入
- 构建哈希索引的哈希函数必须和第一步的哈希函数不同
- 如果构建关系包含
个块,每个划分的大小不超过 ,则划分的数量至少为
实际进行划分之后,我们需要将较小的关系作为 build 所用的关系;
哈希函数的值域决定了分区n的大小, 为了使得si均能存放在mem中,要求 :
其中的
被称为修正系数, 一般设置为 1. 2
递归划分
Recursive partitioning required if number of partitions n is greater than number of pages M of memory.
不需要递归划分的条件:
成本分析

为输入和输出分配缓冲块个数的提示:
two buffer pages are available for each partition during the hash partitioning phase.
此时的
= 2
外排序
cost分析:
- 块传输
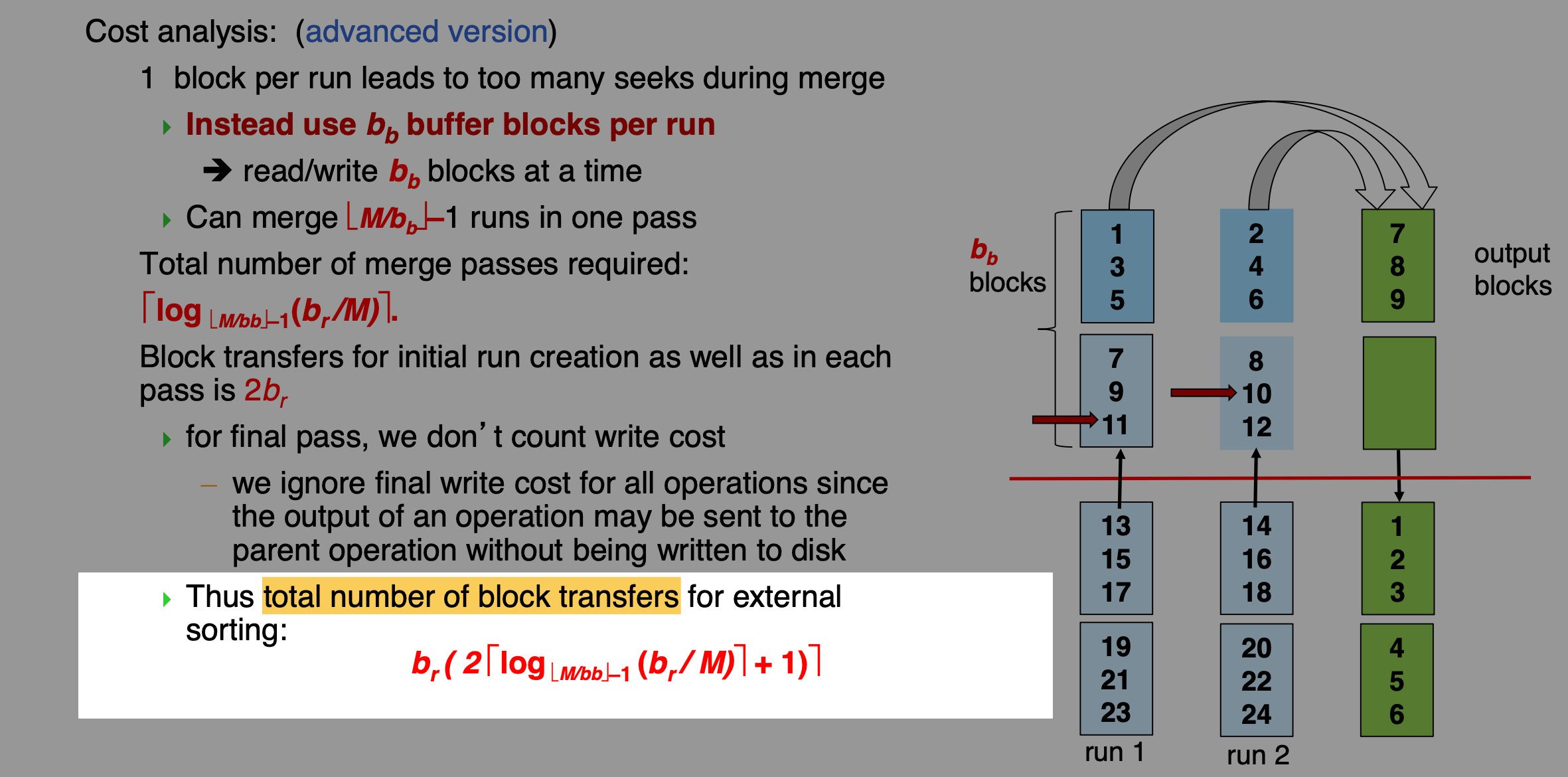
- seek

物化与流水线
- 物化:按照顺序对表达式求值,将中间的计算结果物化为临时关系,并且需要将临时关系表写入disk
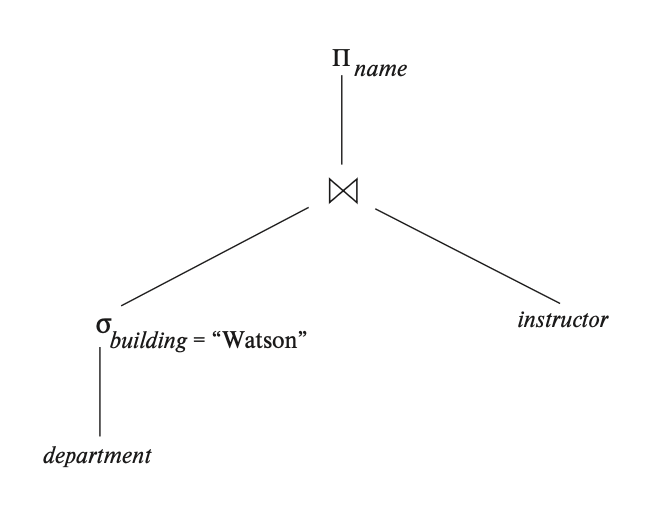
- 流水线:同时对多个表达时求值,将表达式的运算结果立即传入需要的表达式,无需将中间结果写入disk
- 生产驱动型流水线.
- 从下往上主动生成元组.
- 需求驱动型流水线.
- 从最上层的输出, 递归调用下层的函数
next(), 直到最底层为close() - 向流水线顶端的操作请求元组
- 从最上层的输出, 递归调用下层的函数
- 生产驱动型流水线.
Query Optimization
主要参考ppt的习题
并发控制
- 可串行化调度
- 前驱图(优先图)
- 注意绘制需要根据给出的schedule,从上往下看是否存在冲突
- 将事务作为节点, 存在冲突的事务之间建立边,
表示冲突之中,前者的操作先发生,后者的操作后发生;
- recoverable schedule 可恢复调度
- 依赖于T1写入的数据的T2,需要在前者commit之后,后者才能commit
- Cascadeless Schedules 无级联调度
- 每一对存在冲突的事务, 前者事务的提交先于后者数据对的读取
- 无级联调度都是可恢复的.
- 等待图
- 边
表示事务i正在等待后者释放有关数据的锁; 当后者释放这个锁时,将这条边删除 - 当且仅当等待图中存在环时,系统中就出现了死锁
- 边
两阶段锁协议
- 无法保证解决死锁的问题
- 但是按照排序关系来获得锁可以避免产生死锁
- Two phase locking can not avoid deadlock.To acquire locks in partial order of the data can avoid deadlock.
- strict two-phase locking
- 每个事务保持exclusive锁直到结束;
- 可以解决级联回滚和不可恢复的问题
- 根据~得到的调度一定是冲突可序列化的,这意味着如果前驱图存在环,一定不是由~得到的调度
- 按照所有事务的lock point (当前事务得到最后一个lock的时间点)排序,即可得到串行化顺序
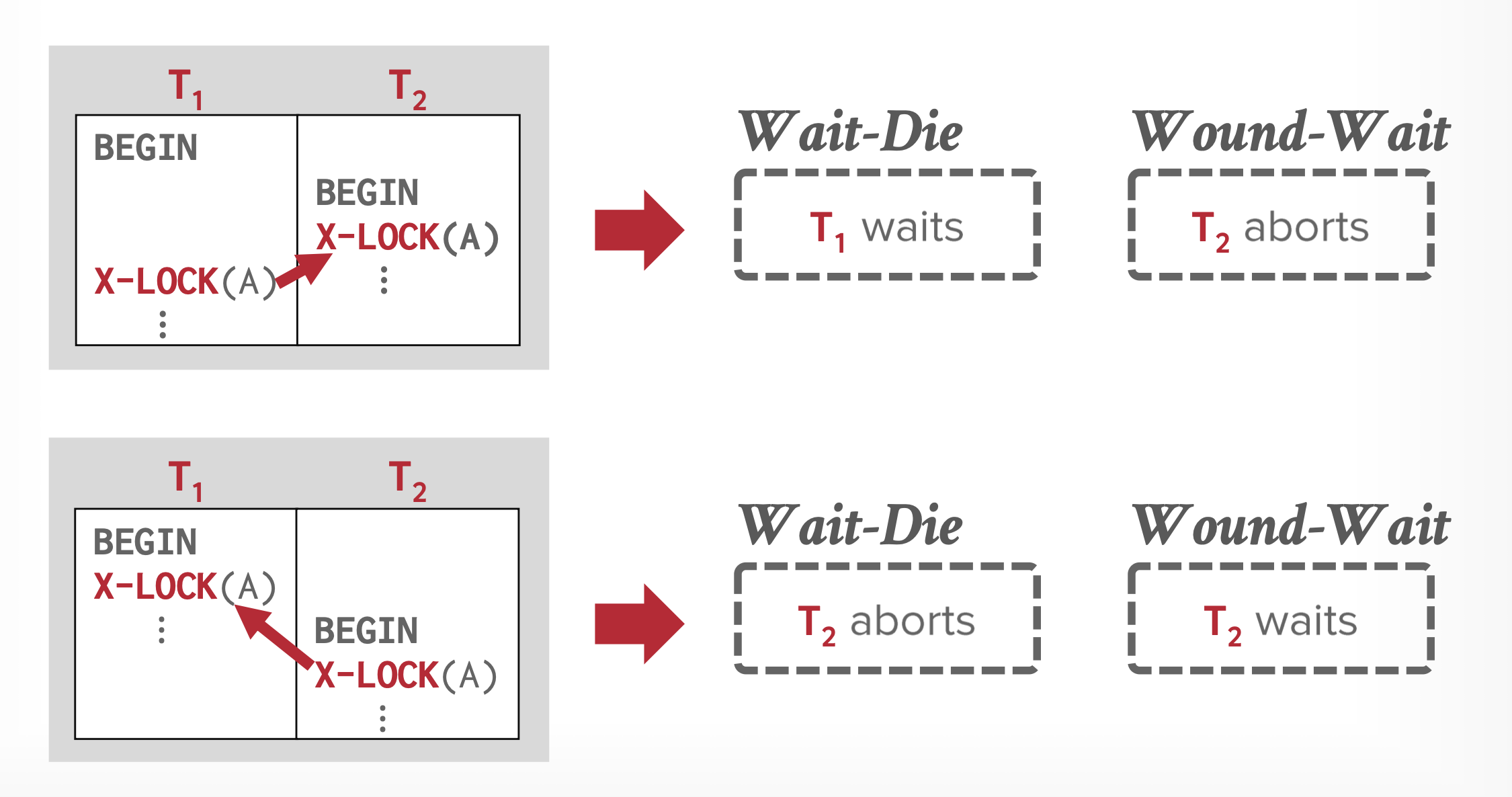
避免死锁
发生冲突的锁请求之间:
wait-die: 如果后者的时间戳更小,i.e. 更早开始begin, 那么后者可以等待,否则回滚后者的操作;wound-wait:反之,后者begin开始得较晚时,可以等待,否则回滚<u>前者</u>(前者被后者击伤)
错误恢复
普通恢复
简单流程
- redo:
- 正向遍历,重做;
- 如果碰到了新的事务就将其加入undo-list
- 如果碰到了事务的commit/abort,就将其从undo-list中移除
- undo:
- 从末尾开始逆向遍历
- undo的时候产生undo日志(注意区分逻辑操作)
- 碰到了undo-list中的事务才undo,并且碰到了对应的start写入对应的abort日志
- 所有的undo事务都写入了abort后结束
checkpoint
- 普通的checkpoint:在写入checkpoint的log之前,此前的活跃事务停止更新,直到将buffer里的修改全部flush到disk,才写入checkpoint的log表示更新完毕,然后继续执行
- 这样可以确保,在checkpoint之前commit的事务,其更新一定反应到了disk当中;
- fuzzy-checkpoint:
- 为了避免上述的阻塞而设计,允许写入checkpoint的log之后,可以继续执行日志,同时将先前的修改写到disk
- 但是这样伴随了一个问题,可能有的修改正在写入就发生了crash,我们需要一个机制确保处理这种情况;
- last-checkpoint:将最后一个完成的检查点记录在日志中的位置存储在硬盘上的一个固定位置,即最后检查点。系统在写入检查点记录时不会更新此信息。相反,在写入检查点记录之前,它创建一个包含所有已修改缓存块的列表。只有当列表中的所有缓冲区块都已输出到磁盘后,才会更新最后检查点信息。
undo产生的日志
在逻辑操作中,如果逻辑操作已经完成和逻辑操作未完成,面临回滚时的日志类型不同:
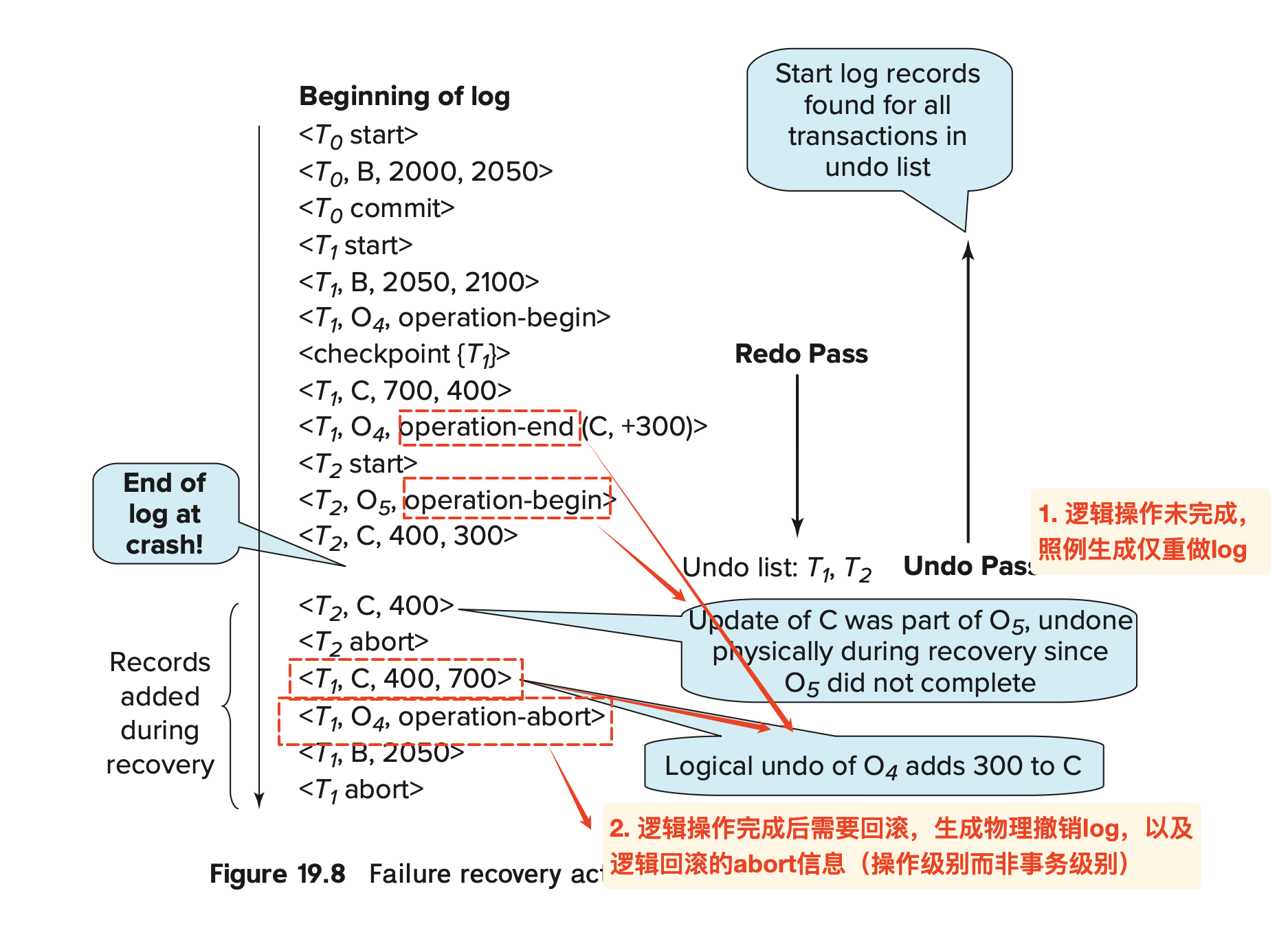
为什么需要operation-abort的信号?
让operation-abort的信号在undo阶段被发现时,直接跳到对应的begin,避免已经在redo期间执行的操作被再次执行
Aries恢复
- 使用LSN标注日志
- 使用dirty page table避免不必要的redo
- RecLSN:第一次变成脏页对应的LSN
流程
- 相比之前的恢复算法,多了第一步的分析阶段:
- 分析dirty table,取RecLSN的最小值作为Redo的起点(如果不存在就取checkpoint的LSN)
- 分析阶段本身是从检查点开始正向遍历的
- 分析阶段同样需要更新dirty table和活跃事务表
- 分析的时候,只会分析log,但是不会读取数据文件page,也就是不会读取page
- redo的阶段与普通恢复整体相同:
- 发现更新记录的时候,如果不在脏页表中的page之列,or 更新记录的LSN小于页面的RecLSN,就忽略;
- 否则,我们需要读取page,然后再比较pageLSN与log LSN;
- 如果log LSN 大于 页面的pageLSN就redo
- 发现更新记录的时候,如果不在脏页表中的page之列,or 更新记录的LSN小于页面的RecLSN,就忽略;
- undo阶段
- 为了撤销undo-list中的事务,利用分析阶段得到的lastLSN(选择最大值作为起点),开始反向遍历重做
- 重做的时候也会生成仅重做日志的CLR,但是不同之处在于:
- ARIES算法的CLR还会在字段UndoNextLSN中记录该事务当前LSN的prevLSN
- 这是为了应对undo过程中crash情景:可以利用CLR知道下一条undo的LSN后,继续undo
- 实际上做题的时候,往往不会呈现上述的
xxLSN,而是类似于普通恢复的仅重做日志,类似于:1
2<T4, 102.1, 62>
<T4, abort> - 符合下列条件的记录可以跳过:
- TODO
简单的例子
演示了xxLSN的作用:
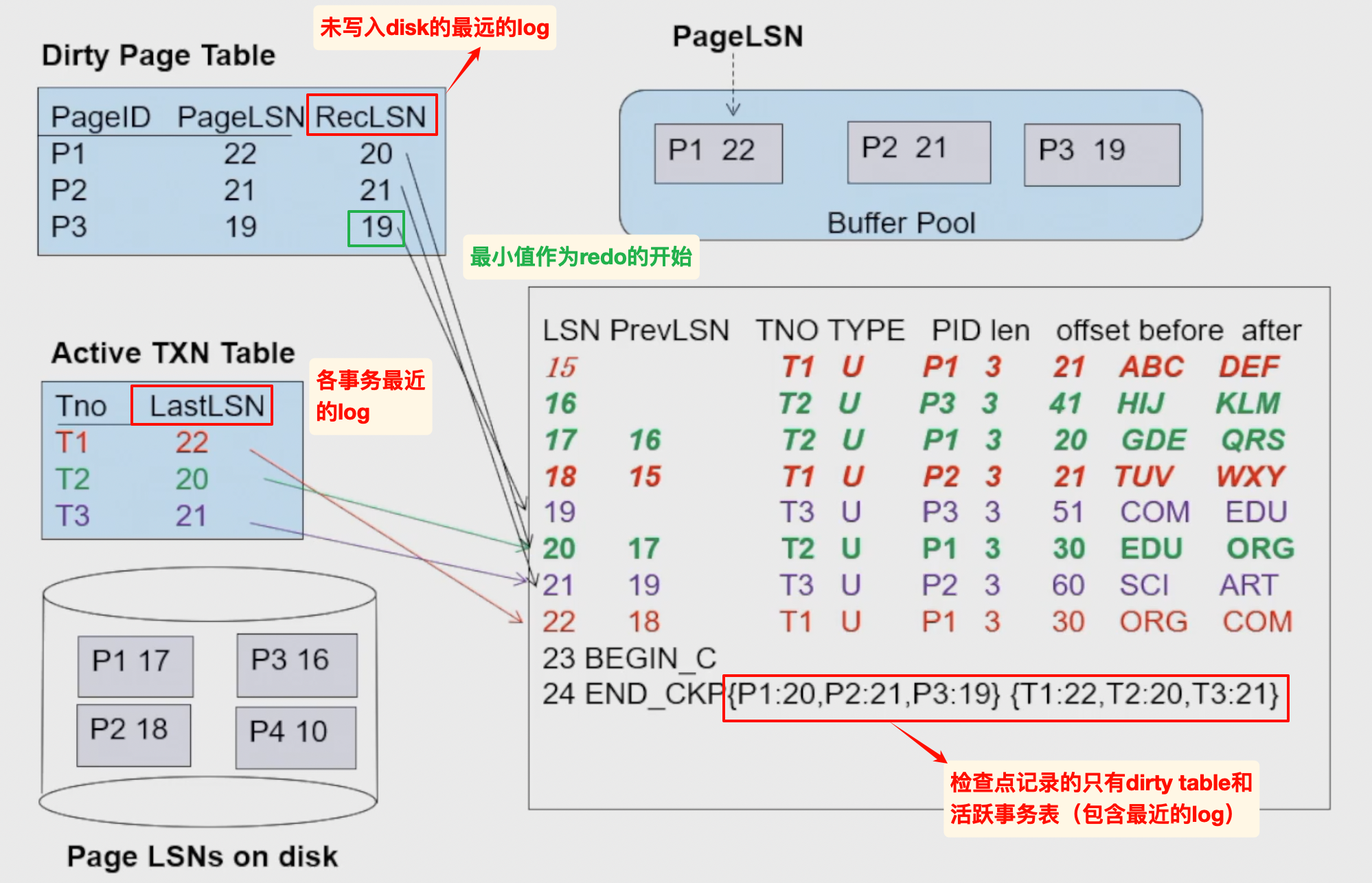
TODO:教材中声明了脏页表储存了pageLSN,如果DirtyPageTable已经包含了pageLSN,为什么还要从disk中读取page再比较pageLSN和当前log LSN?
因此在redo阶段,需要首先比较当前LSN与RecLSN,如果可能需要修改,就读取对应page,然后比较其pageLSN与当前LSN的大小
课本的例子
演示了算法的具体流程:
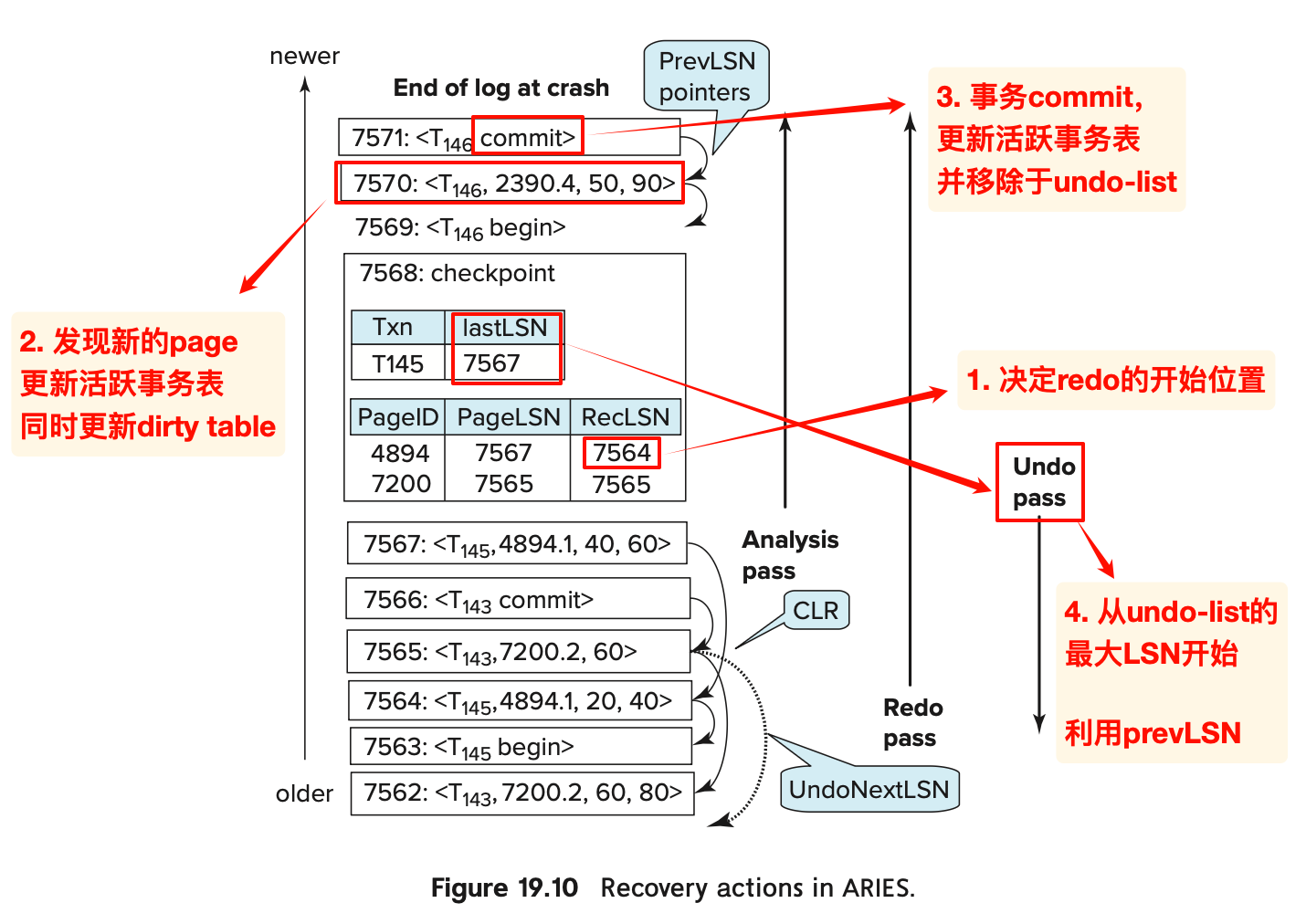
CLR不需要写abort
在事务commit的时候,不一定需要将数据都flush到内存中
- 事务总是可以写log
- flush的时候,先将日志flush到内存中,然后将数据flush到内存中
undo产生日志的时候,也是一条一条产生仅重做日志的,不会从末端沿着prevLSN直接回溯到最开始)比如:
1 | <T3, 8002.1, 66> |
习题
SQL练习
- 使用聚合函数时不一定需要
group by; - 注意符号:不等于
<>
练习1

主要关注第四题:
1 | select title from movie |
- 题目的意思是:找出给xx打分的都比给
the avenger打分高的xx(电影title)- 考虑使用
except,涉及到单表之间的比较,因此将2个comment作笛卡尔积- 利用title确保与外表相连接;利用user_name确保2个内表讨论的是同一个用户的打分
练习2
题目:

第一问:将给出的SQL查询转换为不包含嵌套子查询的版本
1 | SELECT DISTINCT C.cno, C.name -- 使用 DISTINCT 是为了避免同一张 CS 卡因有多笔交易符合条件而被多次列出 |
第二问:转换为代数表达式:

第三问:编写SQL语句,找出2018年仅在一个校园中使用的卡片
1 | select cno |
- 注意
detail中就有cno的信息,因此不需要和card表join
第四问:写一个SQL语句,找出2018年“紫金港”校园中具有最大卡消费总量的pos。
使用
having子句的版本1
2
3
4
5
6
7
8
9
10select pno
from detail natural join pos
where pos.campus=’紫金港’ and year(detail.cdate)=2018
group by pno
having sum(amount) >= all ( -- 注意这里的比较
select sum(amount)
from detail natural join pos
where pos.campus='紫金港' and year(detail.cdate) = 2018
group by pno
)也可以搭配
order和limit 1直接筛选:1
2
3
4
5
6select pno
from detail natural join pos
where pos.campus=’紫金港’ and year(detail.cdate)=2018
group by pno
order by sum(amount) desc -- 注意这里是 sum(amount)
limit 1这种操作带来的差异是,如果存在多个相同的最大值,还是只会选择一个,所以比起使用嵌套子查询还是有劣势
第五问:编写一系列SQL语句来完成以下事务:卡片“c0002”在pos“p001”处消费20,时间为2018-07-02 08:08:08
1 | update card set |
- 注意需要同步更新card;
- 需要commit
范式相关
无损分解
- 课本的定义:

具体的验证,可以采取计算属性闭包的方式来推导
- 一个简单的例子:

如果分解的结果不是两个,而是多个关系,并且给出了分解的过程(可能是自己推的),那么可以每次对中间结果判断一下是否满足无损分解,如果都满足就认为整体是无损分解的;
dependency-preserving
回顾课本的定义:
- the set
of all functional dependencies in that include only attributes of Ri - 也即是将R进行分解为Ri之后, Fi是F的闭包中存在于Ri相关属性的部分.
- 因此, Fi不一定是F的部分.
我们定义 上述的
也就是, 如果F’的闭包等于F的闭包, 则称上述的R的分解为 dependency-preserving decomposition
由此可见,我们判断一个分解是否为依赖保留的分解时,只需要计算对应
- 一个简单的例子:判断上述的分解是否为~

上述的F1还包含了 BC -> A (根据F条件下的属性闭包计算得到)
BCNF分解
根据无损分解的定义,满足BCNF范式的分解就满足了无损分解的要求。(但是不一定满足依赖保留)
- 一个简单的例子:将上述的例子转换为无损分解的BCNF分解

注意,判断是否满足BCNF的时候 ,

满足3NF的分解
3NF在BCNF的基础上多了一条,也就是右侧的属性是候选键的部分。因此,我们需要先借助FD来推导候选键有哪些。
标准的分析流程:
计算F的一个最小覆盖 F_min。满足三个条件:
- F_min 与 F 是等价的(即它们逻辑蕴含相同的 FD 集合)。
- F_min 中没有任何冗余的 FD(移除任何一条 FD 都会改变 F_min 的闭包)。
- F_min 中每个 FD X -> Y 的右边 Y 是单属性的,且没有任何冗余的属性
根据 F_min 构建关系模式:
- 对于 F_min 中的每一个 FD X -> Y,创建一个关系模式 Ri,其属性集为 X ∪ {Y}。
检查是否包含原始关系模式的候选码。检查是否存在某个 Ri 的属性包含了候选键
- 如果存在这样的 Ri,则步骤 2 生成的关系模式集合 {R1, R2, …, Rm} 就是最终的分解结果。
- 如果不存在这样的 Ri,则需要额外创建一个关系模式 R_{m+1},其属性集就是 K。将这个 R_{m+1} 加入到分解结果中。
一个简单的例子:将上述的分解转换为满足3NF、无损和依赖保留的分解
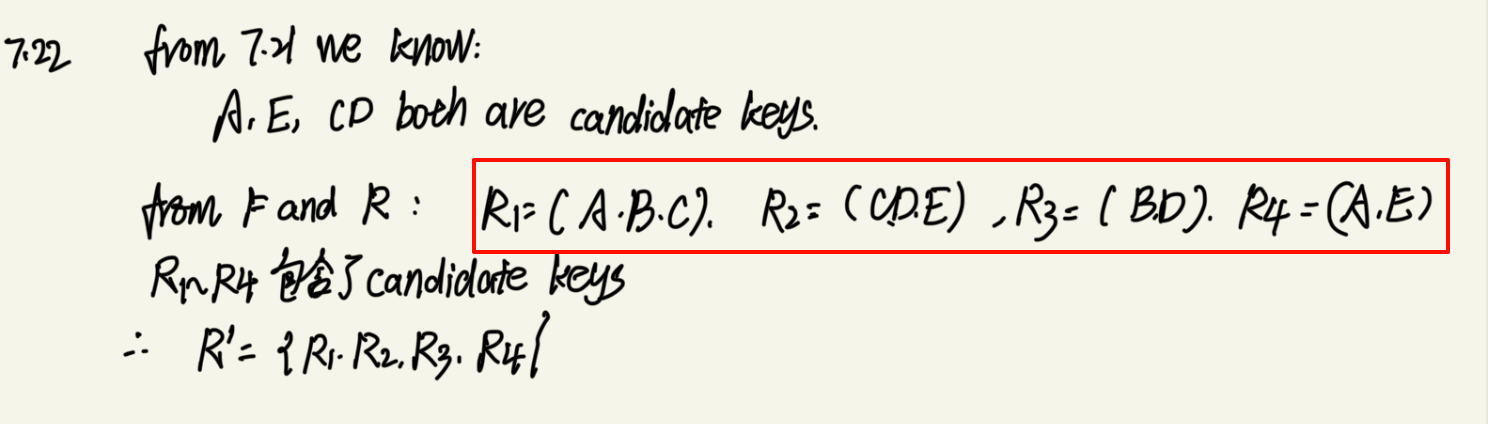
此处的题目给出的F已经是最小覆盖的Fc,因此可以直接用于分解
ER模型练习
根据描述绘制ER图
- 题干将会给出主要的实体集,我们需要根据描述推导蕴含的关系
- 同时需要注意其中的数据类型,比如多值和复合等的格式
一个简单的例子:

第一问:绘制对应的ER图
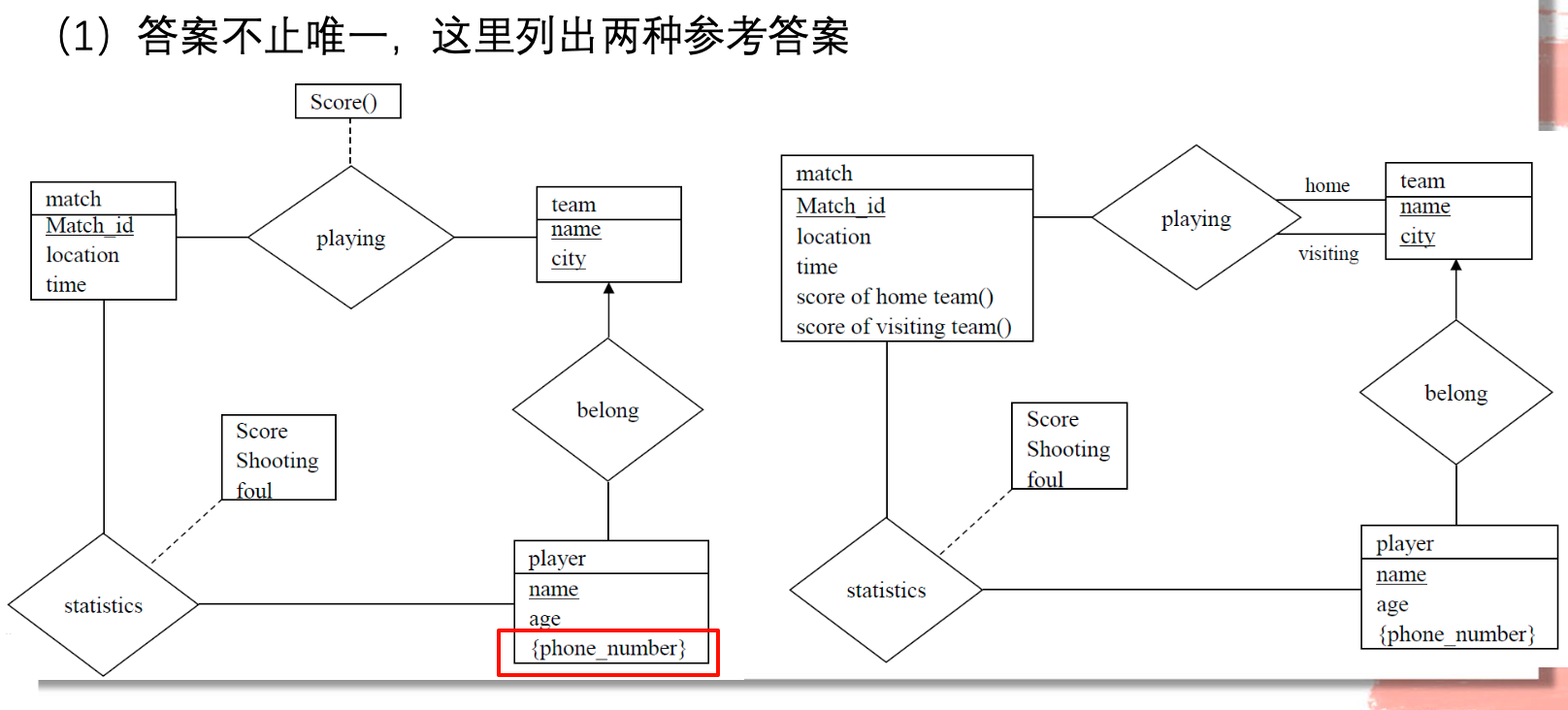
此处的多值属性(电话)由
{}包裹。
由ER图得到schema
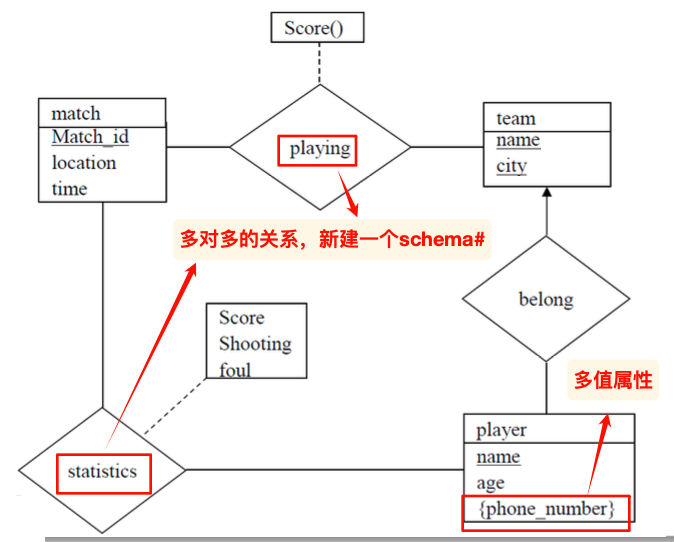
对应的schema:

注意:此处的关系中,1对N的belong没有新建schema
修正:
player中的属性应该增加team_name作为team的外键
B+树练习
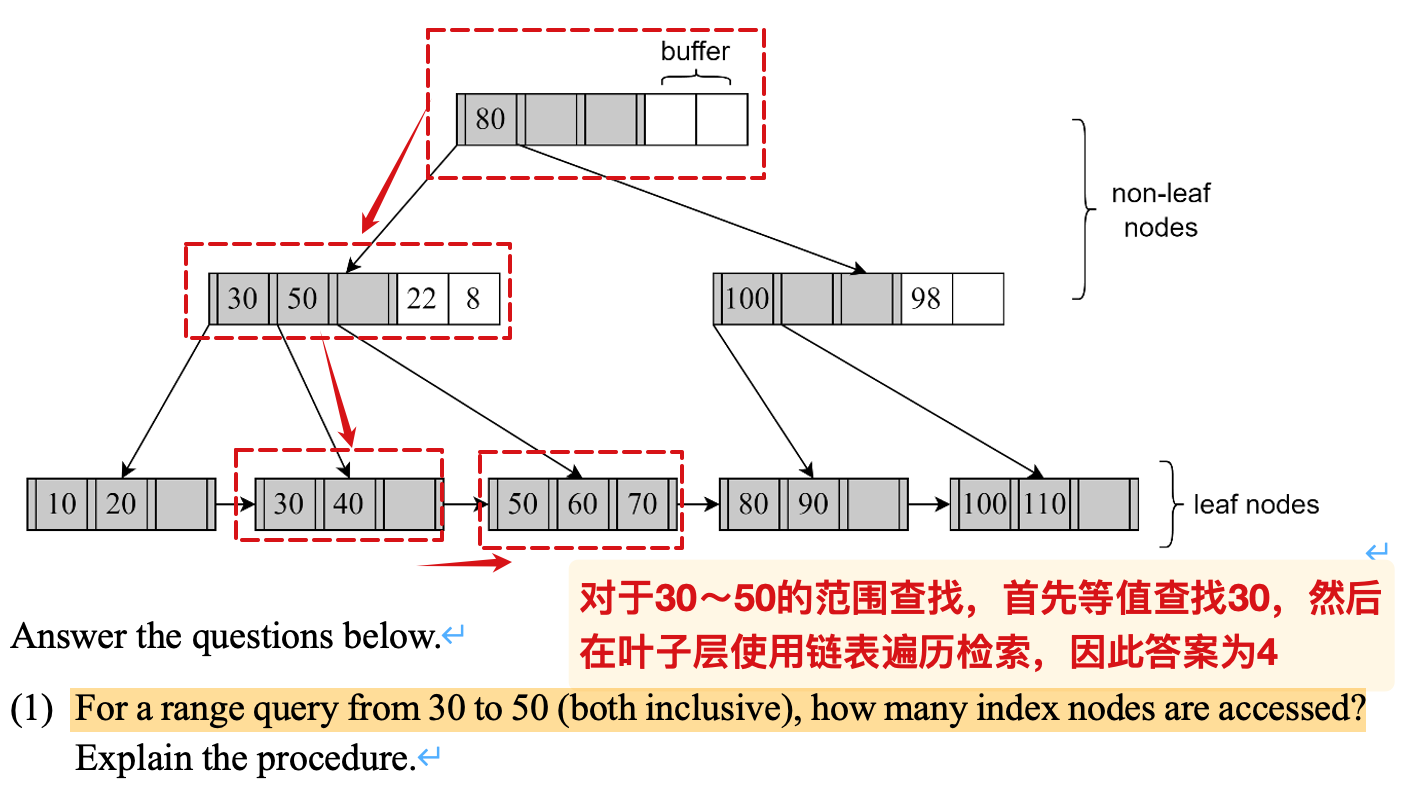
计算B+树的高度
- 通过计算不同高度的最值,来得出最终的高度:
此处计算block并没有作用,实际上是比较索引项
关键是记住:
- 叶子节点的key范围是
~ - 内部节点的~是
~ , 并且根节点的最小值是2
- 我们也可以通过扇出n以及索引项来直接利用对数计算进行估计
关键是理解左右两侧的含义:
计算最小高度时,我们自底向上地构建全满的B+树,先将k个value按照n-1的规模打包,然后每层n个,因此是
- 其中左侧是迭代的次数,因此需要+1补充底层的层数;
计算最大高度时,我们自顶向下地构建半满的B+树,并且在一开始将根节点特殊处理——只分配两个child,所以我们从第二层开始计算,需要迭代的次数为
, 同理需要+1得到从第二层到叶子层的高度数,最后+1加入根节点的高度:
对于上述的推导,我们可以结合第一种方法来给出第二个证明:
取左侧计算得到:
为了满足不等式的条件,应当向下取整
取右侧计算得到:
直接利用给定的高度h计算size:
max:
min:
然后利用题目给出的索引项个数建立不等式
实际上,我们在估算的时候可以忽略常数的影响,比如:
根据索引项估计节点数量
关键:利用扇出n估计最后一层的节点数量,然后倒推
- 估计最少值时,由
计算得到叶子节点的数量N,然后逐步倒推 ,直到加数为1到达根节点(过程中的计算结果向上取整,因为小数部分的节点数无法再纳入其他节点) - 估计最大值时,将上述的除数都换成对应的最小值
与 ,但是注意将每次的计算结果向下取整!因为小数部分的节点数表示无法满足最少个数的要求,无法独立构成节点
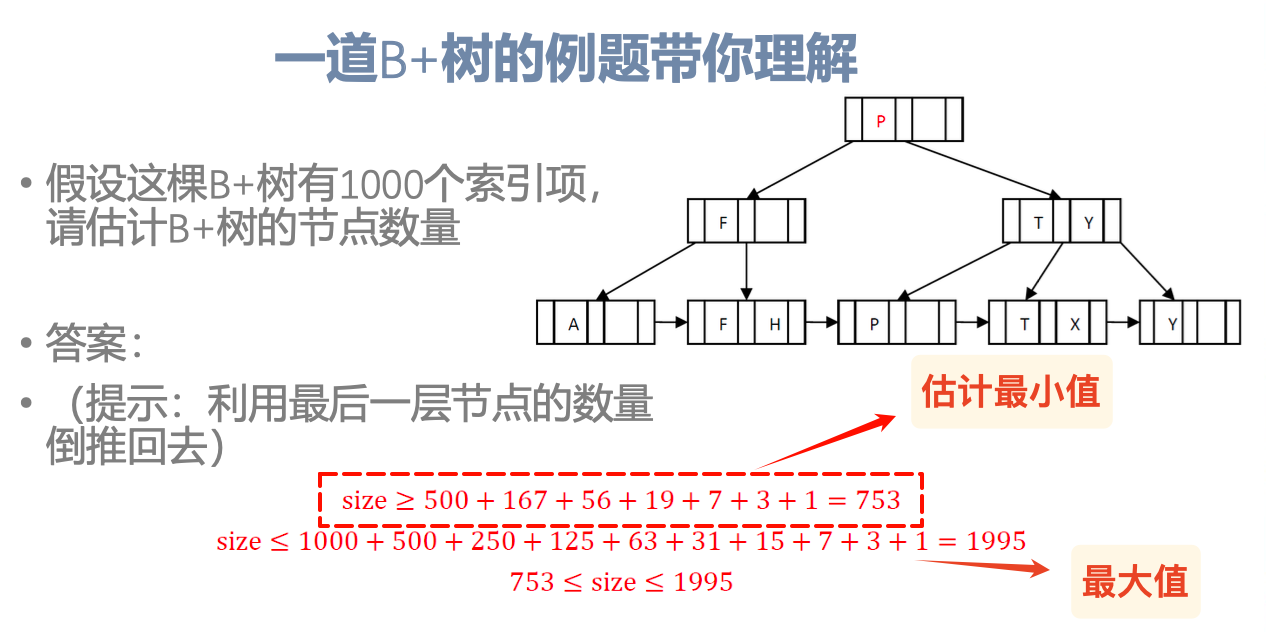
注意取整方向的差异:估计最少向上取整;估计最大向下取整
上面的例题中,max估计的63应为62
计算块传输的次数
题目可能给出一个现有的B+树结构以及一系列的访问操作,结合一定的replacer策略,让我们计算块传输的次数,需要注意的是:
- 如果题目明确说了是 blocks transferred to buffer 那么我们就不需要考虑将block写回到disk的次数
一个简单的例子:
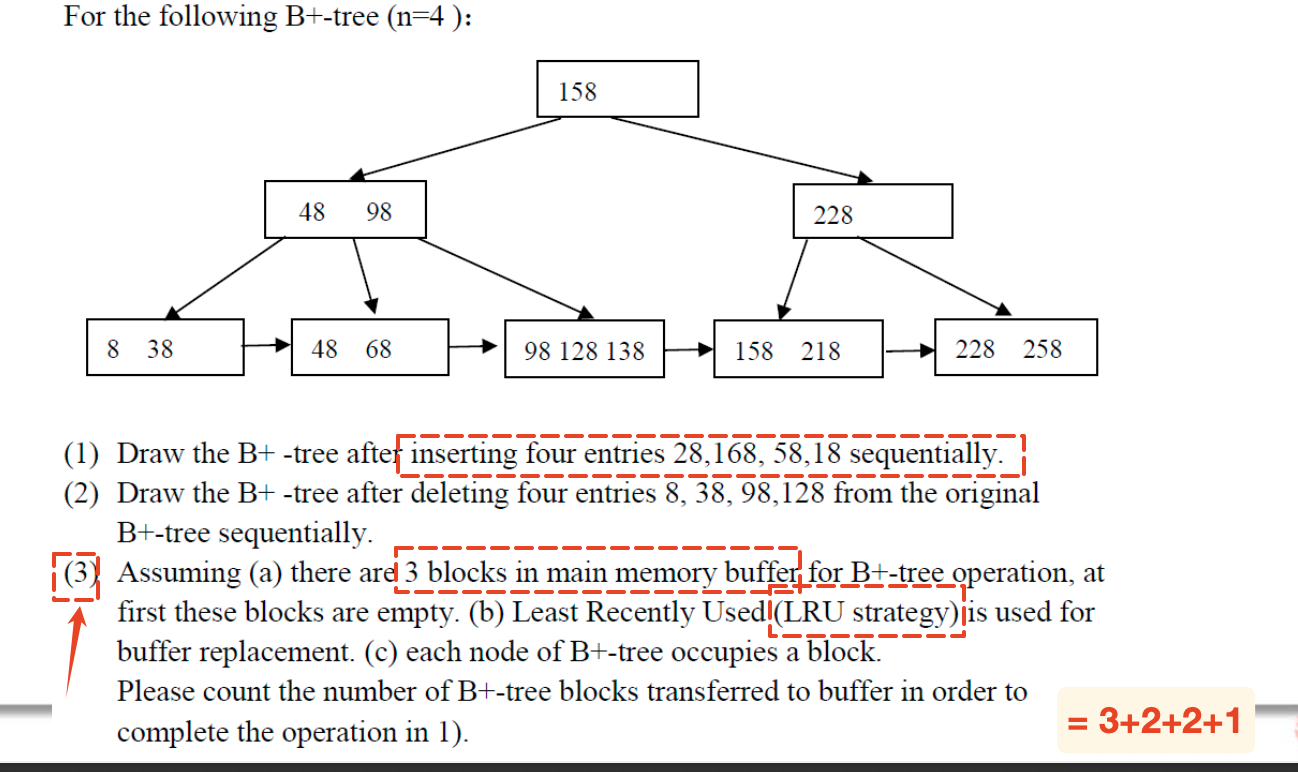
注意此处内部节点的指针数和key数量
删除操作
一般来说,分裂时默认左侧的节点元素不少于右侧节点包含的元素个数,可能题目会具体说明右侧不少于左侧。
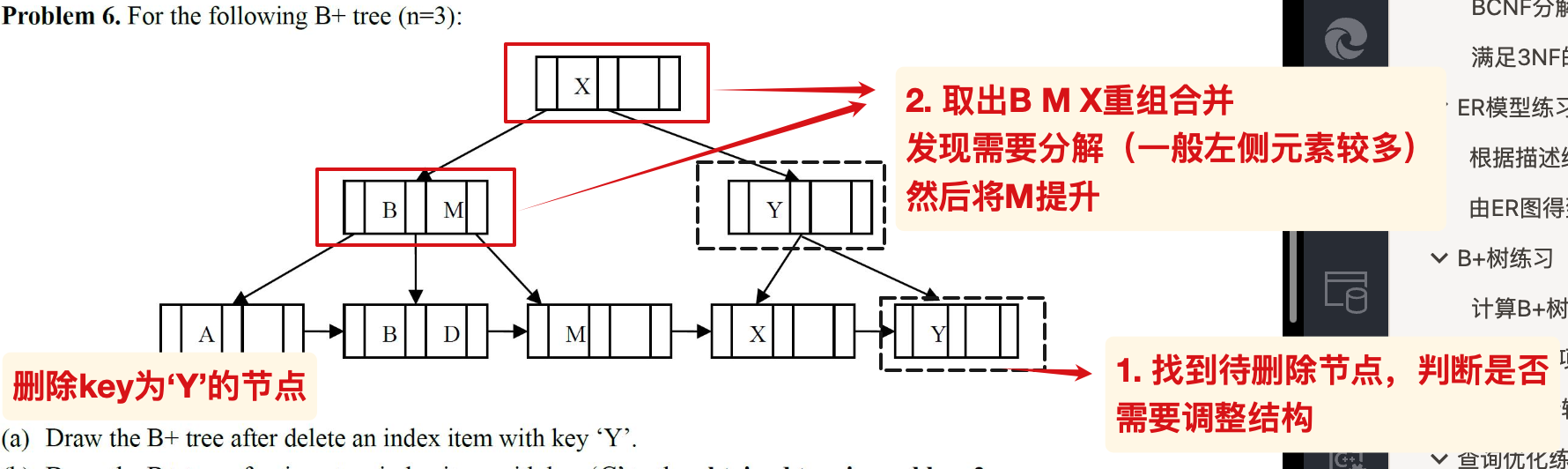
重组 合并 发现需要分裂
LSM的成本估计
问题:

(3)对应的B+树:
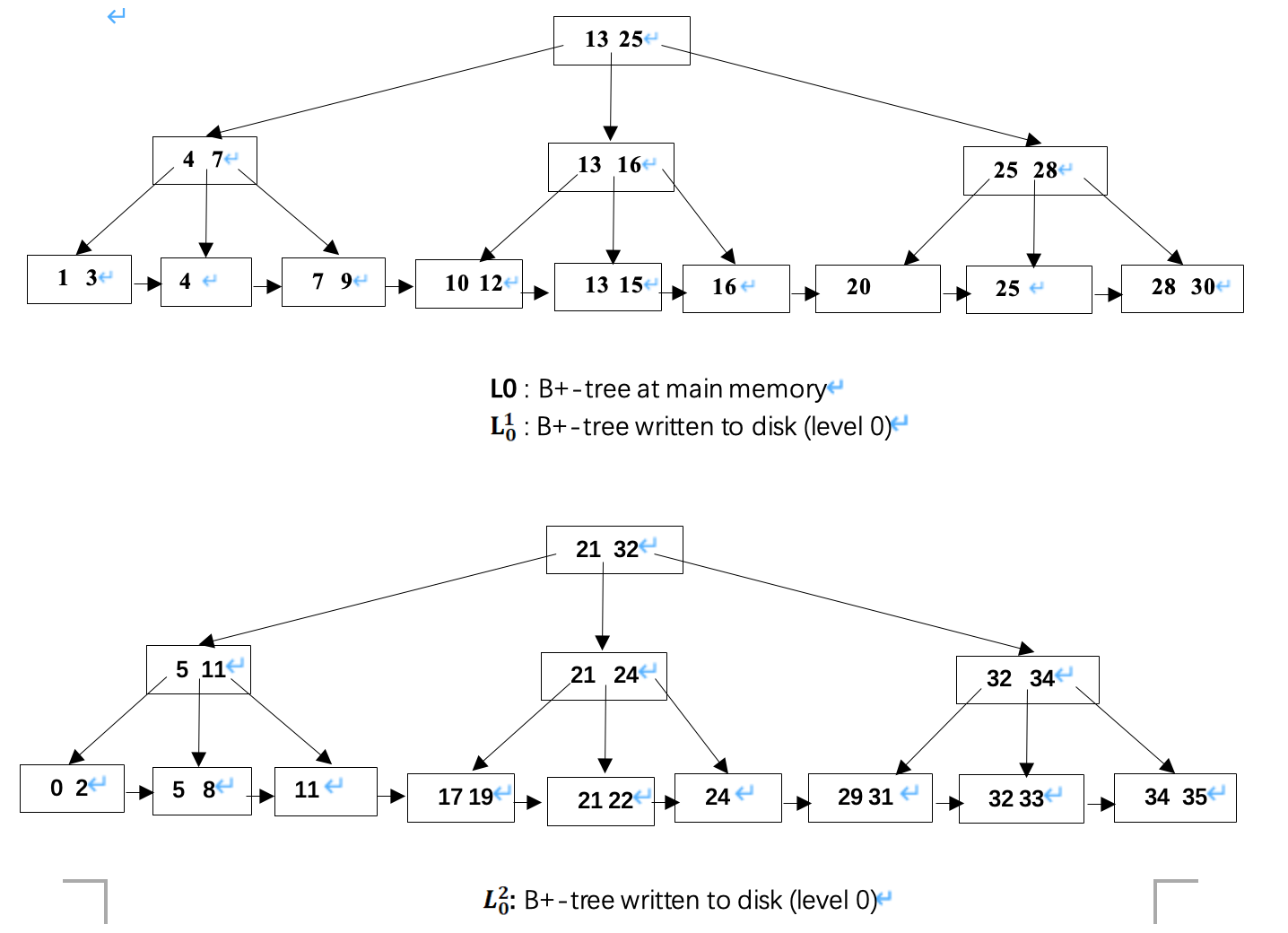
ans:

TODO:(2)是什么意思?
题目说maximize size = 13, 根据 1 + 3 + 9 = 13, 推知最多有3层高
查找某个index,可能的范围分别是主存以及disk中的两棵树,分别计算对应的成本,然后加权求和:
- 根据上一步计算得到的B+树的高度,如果在主存中,块传输和寻道的成本都是0;如果在第一棵树就是3+3, 在第二棵树就是前面成本的两倍
- 因此整体是 (0 + 3 + 6) / 3 = 3(块传输和seek)
为什么不需要计算从叶子节点到disk的额外寻道和块传输?
- 因为题目声明了:look up an index entry ….
- 这意味着,我们只需要检查某个index是否在叶子节点中包含,所以只需要查找到叶子节点层,不需要根据叶子节点中的指针访问disk中的数据页
查询处理练习
join的成本估计
这里什么都没有哦~
查询优化练习
如果题目只是给出了两个关系,让我们计算对应的join成本,我们应该先计算关系各自的block数量,然后选择块较少的作为外层关系
- 这是因为此时对应的块传输次数和寻道次数分别为:
如果给出了缓存区的buffer大小
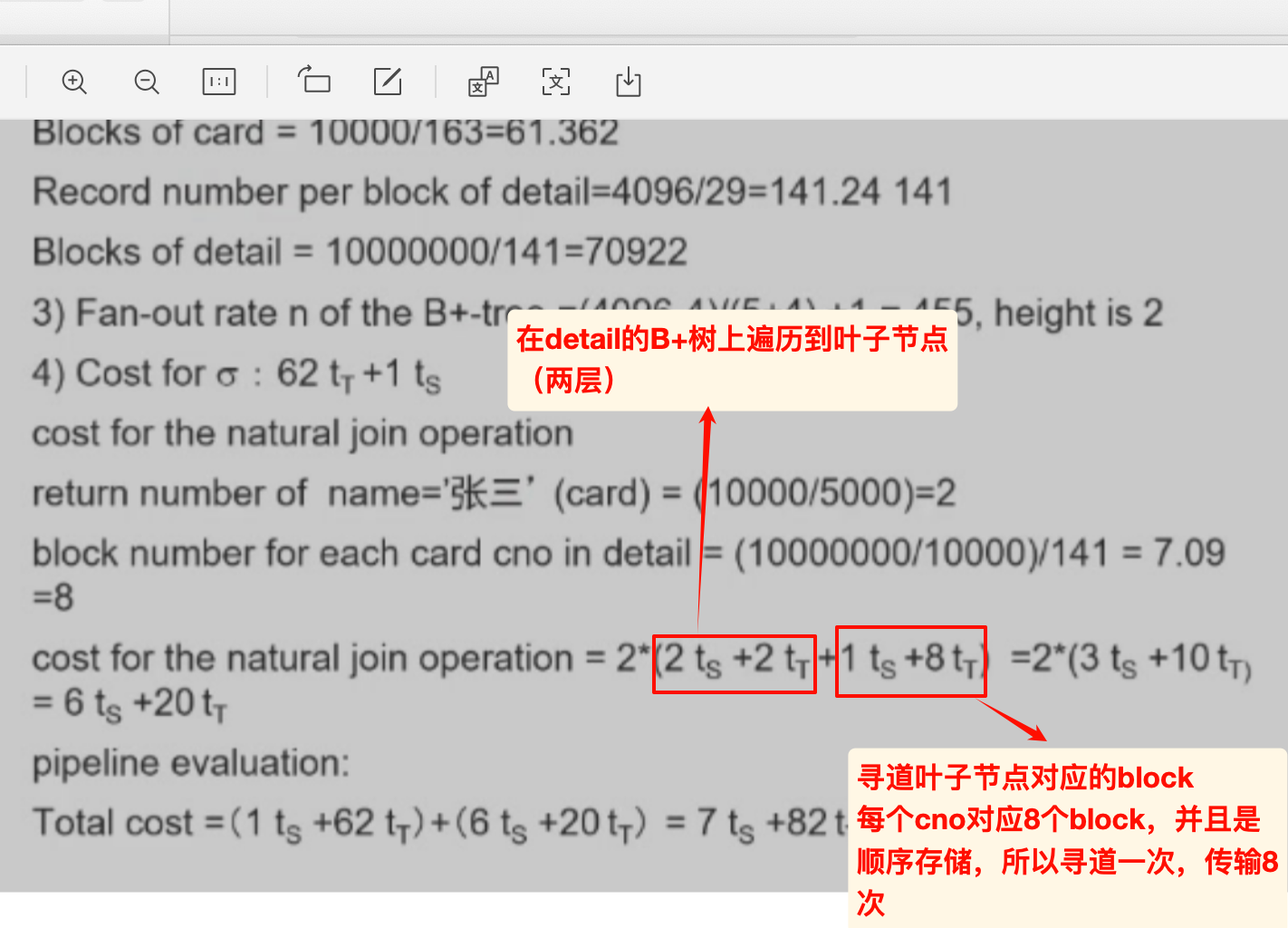
习题1

具体解答参考:
where中包含了join的条件, 因此此处的join属性实际上是pno和cdate, 计算对应的V.
- 实际上是一组复合的属性, post有100个, cdate有365个可能的取值. 因此估计对应的值域空间是100*365.
/4对应了where中最后一个时间的约束, 是整体的1/4.1个block的尺寸是4096bytes, 除以每条记录的尺寸, 得到每个block对应的记录数量. 然后据此计算table对应的block数量.
cno的bytes是5, 根据题意==> pointer的大小是4bytes, 那么每一对键值对是5+4=9bytes.计算 fan-out-rate n = 455,然后根据公式算出高度为2(注意是建立在cno的索引,不同的cno有10000 = K个,据此计算!)
根据detail的记录数量, 估算每个card对应的记录数量. 然后根据detail的block的容量, 计算每个card对应的记录的block数量.
- 根据
V(name,card)= 5000 我们可以知道, 因为card中一共有10k条记录, 所以每个名字平均对应2个card.- 参考

习题2

(2):

优化的分配是:1块给输出,1块给内关系,剩下都分配给外关系
(3):TODO

SOLUTION:
K = 5000, n = 60,计算得到高度为 3(答案中max的估计公式有问题,并且应该是向下取整)
注意此处题目说了为root准备了一个buffer,在每次的遍历中原本的h+1 = 4的成本 减去1次,只需要在一开始存入(最后+1)
公式
中的 需要除以500,因为 确定了director(一共有500位不同的~),或者我们可以从成本估计的角度解释:
归并排序练习

此处的buffer容量是针对于run的, 也就是output存在2个block; 可以计算得到 (10-2) /2 = 4 ,每次将4个run归并
SOLUTION: 如何计算seek?
分析:
- 此处为每个input row 提供了 2 buffer block意味着我们每次seek之后可以直接读取2个blcok而非1个(优化), 从而减少了seek的次数;
- 利用每次归并4个runs, 得到总共的pass数量
- 注意题目说最终需要写回到disk
解答: (ljm同学的珍贵手稿)

可以直接运用公式, 此处的
= 2, = 10, = 160:
其中加红的,表示需要写回disk的额外成本,如果题目没有明确声明,就不需要加入计算
并发控制练习
绘制前驱图
可以根据数据项分组,从当前向下查看:
习题和解答:
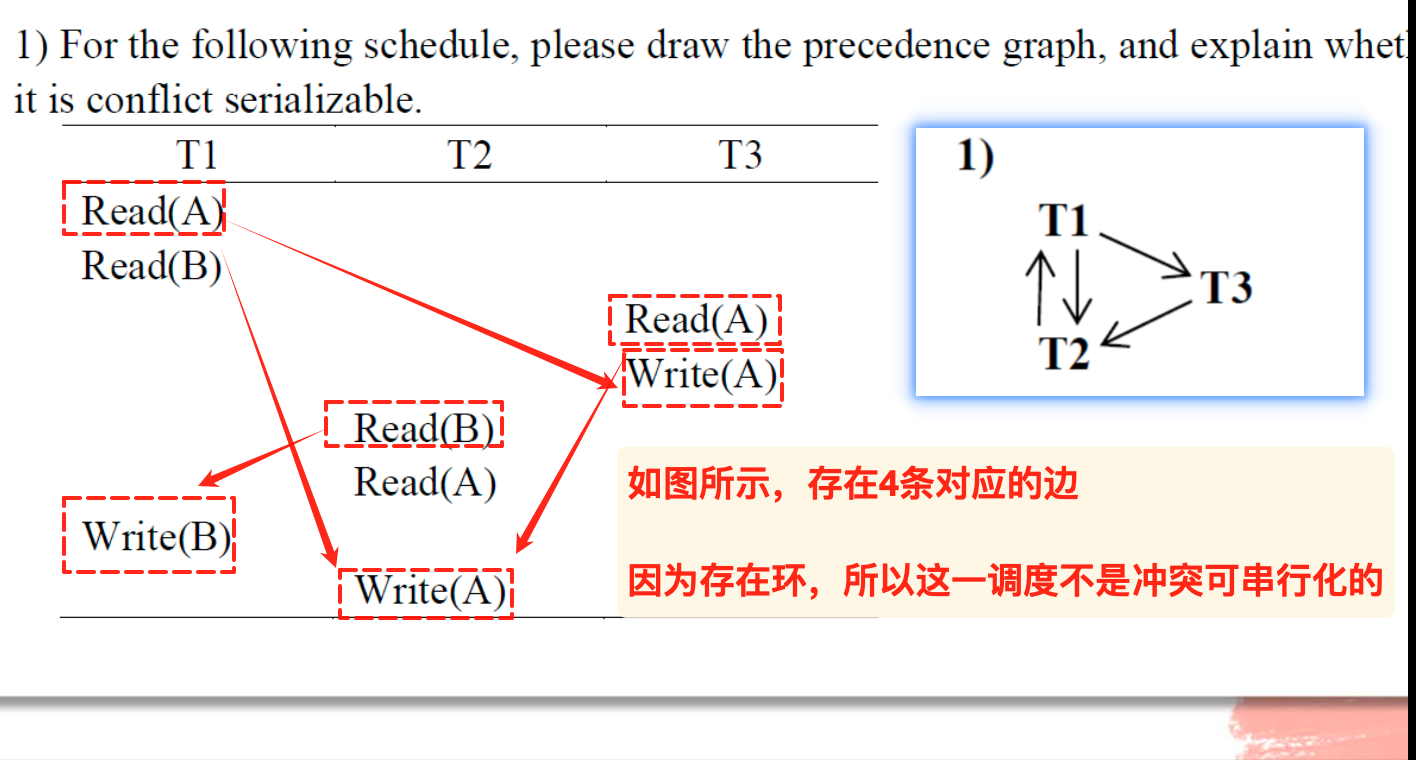
判断是否为无级联回滚的调度也很简单,只需要保证读取在提交之后即可,比如:
2
3
4
5
6
7
8
9
10
11
-------------|--------------|-------------
Read(A) | |
Read(B) | |
Write(B) | |
Commit | |
| Read(B) |
| Read(A) |
| Write(A) |
| Commit |
| Read(A)两阶段锁协议无法解决死锁的问题
等待图与死锁
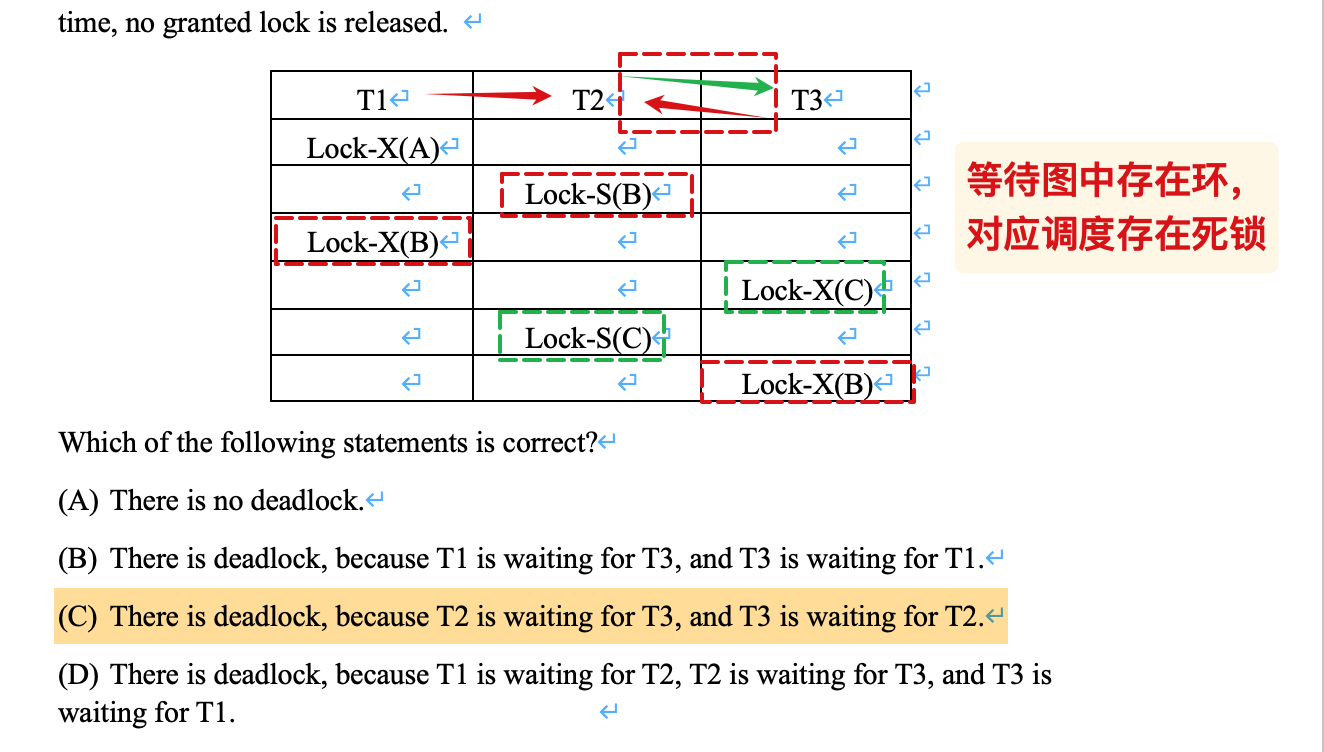
注意题目说了,此时还没有事务释放锁;T3没有指向T1的边,因为此时T1没有对B成功加锁
错误恢复练习
脏页表的更新
| PageID | PageLSN | RecLSN |
|---|
- 如果有新的页面被更新了,加入脏页表,同时设置对应的PageLSN, RecLSN等于当前的log LSN
- 只有flush的时候才会清除脏页表中的page entry(我们无法知道什么时候flush到disk,因此一般只增不减)
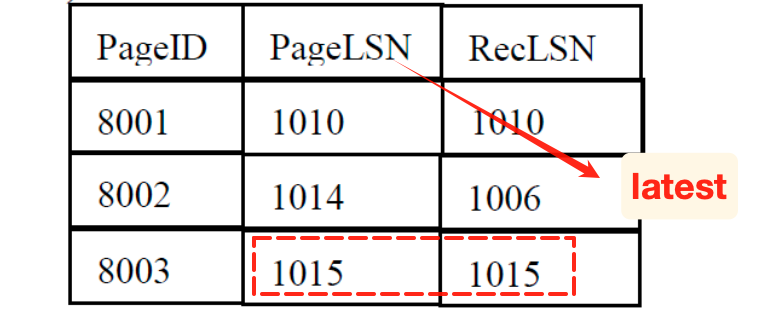
补充
不同的范式
第一范式 表中的每个字段都是不可再分的最小数据单位,即字段具有原子性;
- 如果存在多值属性,需要将其分割位多个单独的
第二范式 消除非PK属性对于key的部分函数依赖
A->B: B 依赖于A- 如果主键是复合的,确保所有非PK属性完全依赖于整个主键,而不是主键的一部分
第三范式 消除非PK对于key的传递函数依赖
- 确保所有非PK属性都直接依赖于PK
BCNF范式 消除PK对于key的部分与传递函数依赖
TODO:补充与理解
SOLUTION:书上没有啊?
Columnar Representation
列式存储在数据查询方面表现更好,但是在事务处理方面表现较差

hybrid row/column store: 支持行列两种存储方式的数据库
根据drawback, Reduced cost of tuple deletion and update的说法是错误的
线性搜索与index
我们根据比较运算符来判断是否需要使用index:

冲突可序列化与2PL
- 遵循2PL的事务调度一定是冲突可序列化的;
- 所有在树协议下合法的调度也是冲突可序列化的
- 但是满足冲突可序列化的事务调度不一定遵循两阶段锁协议
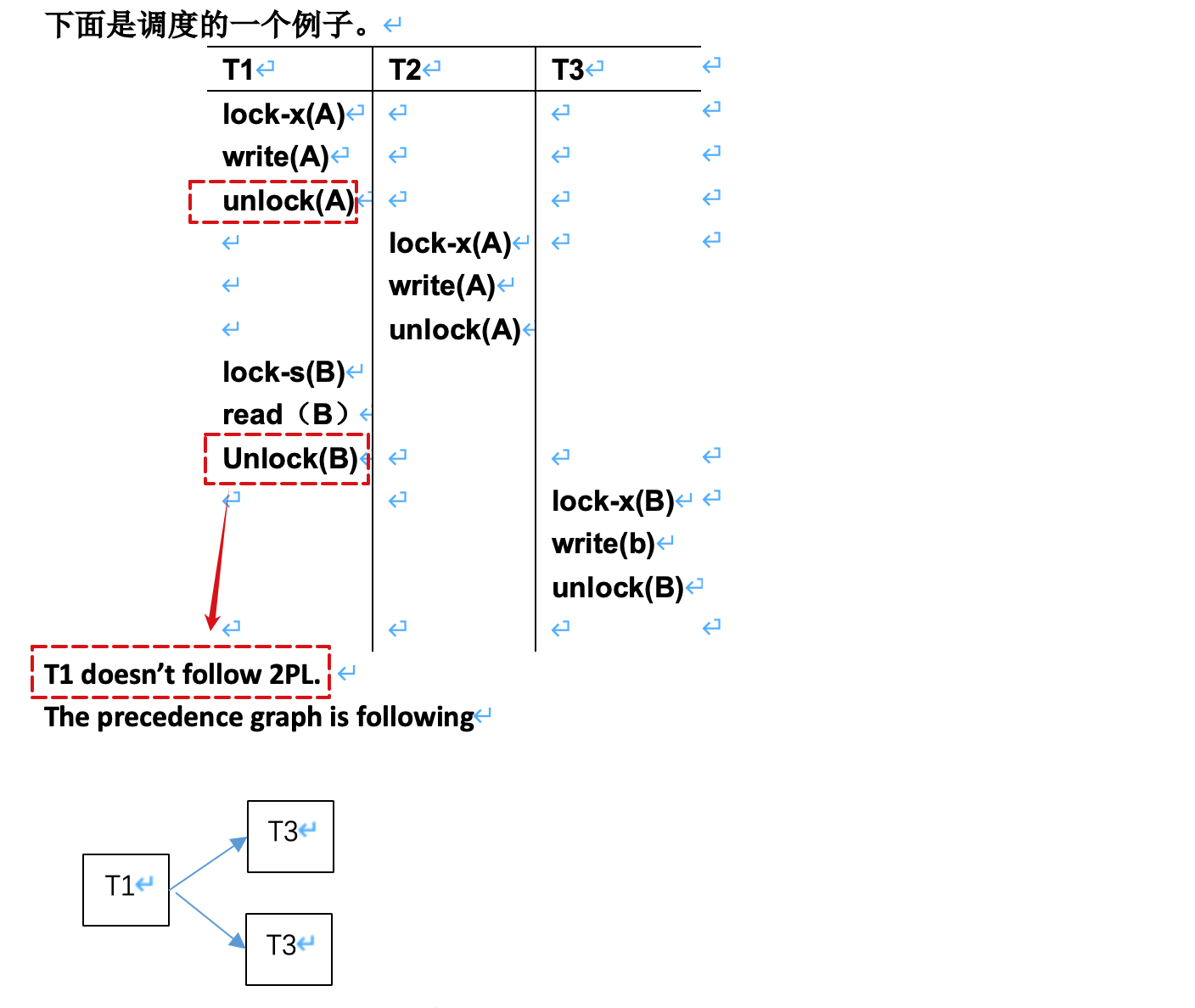
范围查找
redo-list

abort的事务也应该被排除在redo-list之外
小贴士
- 计算B+树的扇出时,键的大小是按照search-key,也就是PK的大小来计算的,不要将关系中的所有属性相加😇
- 绘制B+树的示意图时,记得在叶子层补充链表结构
- 进行结果集大小估计时,发生在候选键上的等值查找,结果集大小应当为0或1
- 给出记录数量、每条记录的size以及block的大小时,应该先计算每个block所包含的记录数量(向下取整),然后计算所需的block数量(向上取整)
- 直接利用总数量计算总容量然后计算block数量有误,因为这样导致了不同block之间可能存储了同一条记录(的部分)
- ACID:
- 原子性 (atomicity)
- 恢复系统
- 一致性 (consistency)
- 由ADI和合适的约束条件(触发器等)实现
- 隔离性 (isolation)
- 并发控制
- 持久性 (durability)
- 恢复系统
- 原子性 (atomicity)
- relation:行, relationship:表
- Access time: The time it takes from when a read or write request is issued to when data transfer begins
- = seek + rotation time
- steal策略:checkpoint之前的修改都已经反应到了disk(无论对应的事务是否commit)
- 无法确定checkpoint之后发生的修改是否flush到了disk
- 不能对辅助索引使用稀疏的策略!
- 辅助索引对应的search-key一般不是文件排列的顺序;
- 如果只是对部分的记录建立辅助索引,那么无法通过相邻的辅助索引来index得到没有建立索引的记录
- 只能对primary/clustering key使用稀疏索引
- 因此我们有两个结论:
- 稀疏索引只能用于顺序文件
- 辅助索引只能用于密集索引
PPT回顾
- Simple checkpoint stops all active transactions, write out all the updated pages, and restart transactions after completing
导论与基础
数据库系统的目的
直接建立在文件系统上的数据库应用导致:
- Data redundancy(数据冗余)and inconsistency(不一致)
- Data isolation(数据孤立,数据孤岛)— multiple files and formats
- Difficulty in accessing data(存取数据困难)
- Integrity problems(完整性问题)
- Atomicity problems(原子性问题)
- Concurrent access anomalies(并发访问异常)
- Security problems(安全性问题)
数据库的特征
data persistence(数据持久性)
convenience in accessing data(数据访问便利性)
data integrity(数据完整性)
concurrency control for multiple users(多用户并发控制)
failure recovery(故障恢复)
security control(安全控制)
view of data
分为了视图、逻辑和物理模式:
- 视图模式:隐藏了数据类型的细节,也可能出于安全性的考虑而隐藏数据的信息等
- 逻辑模式:描述数据和关系
- 物理模式:描述记录如何被存储
不同模式之间存在对应的映射 mapping
DDL
数据字典:DDL compiler generates a set of table templates stored in a data dictionary
数据字典包含了元数据:
- schema
- 完整性约束
- 主键
- 参照完整性
- 权限
DML
两种数据操作语言:
- 过程式 procedural:描述如何获得信息
- 陈述式 declaretive:只声明需要的数据,但是不说明如何获取
SQL是流行的、陈述式的语言
正因如此,SQL不支持直接通过network来交互,相关的计算和交互需要写在宿主语言 host language 中实现
应用可以通过API或者嵌套的SQL语句来访问数据库(需要宿主语言的支持)
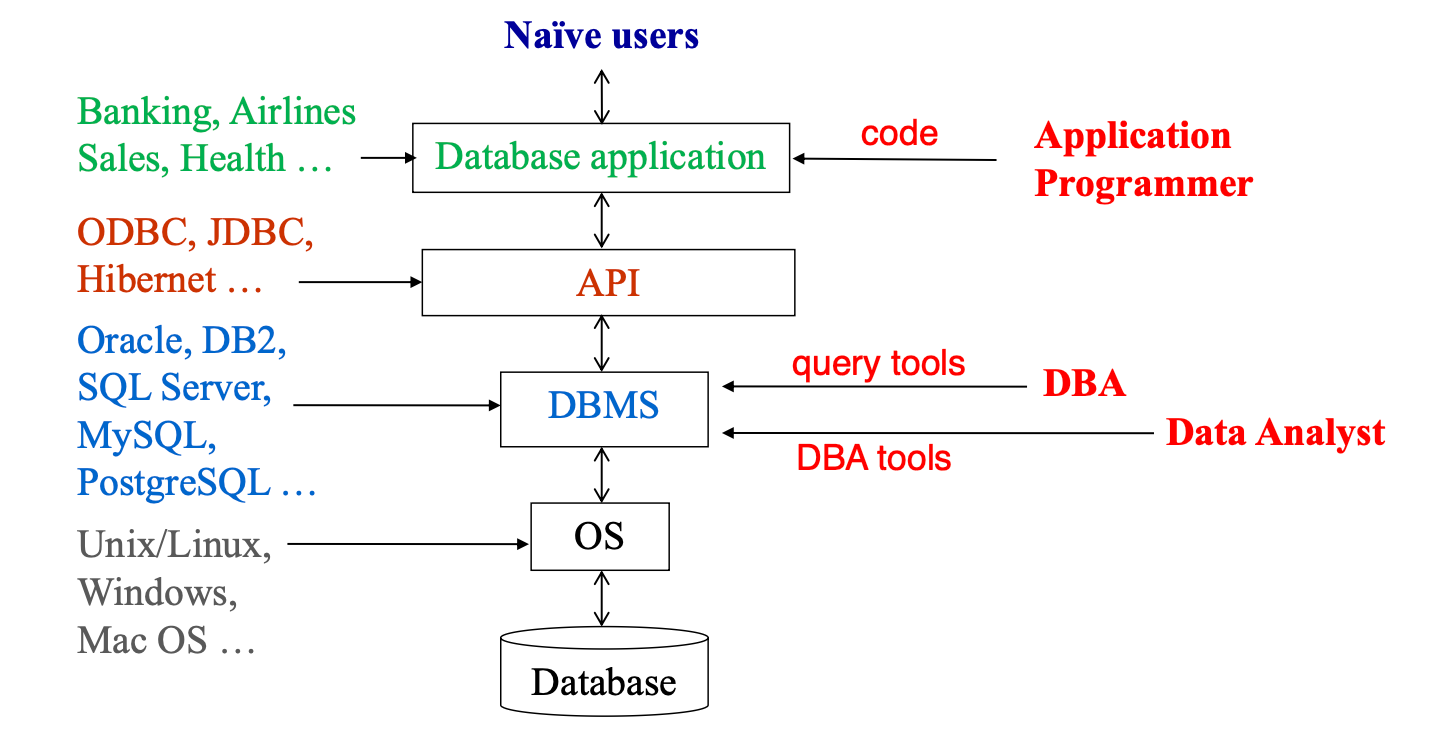
DBA
数据库管理员
DBA的指责:范式的定义、权限的管理、日常的维护(根据表现进行微调、定期将数据备份、确保充分的disk空间)
数据库系统的历史
NoSQL
not only SQL
提供了一种存储和检索数据的机制,这些数据使用比传统关系数据库更松散的一致性模型,以实现横向扩展和更高的可用性。
当数据的性质不需要关系模型时,NoSQL数据库系统在处理大量数据(尤其是大数据)时很有用。
常用的NoSQL DBMs:MongoDB,Cassandra, HBase
NewSQL
寻求为OLTP工作负载提供与NoSQL系统相同的可扩展性能,同时仍然保持传统数据库系统NewSQL的ACID保证:
关系模型
参照完整性:要求参照表中的外键属性一定在被参照表中的至少一个元组中存在
Union要求:
- 两个关系的属性个数 arity相同;
- 对应列的属性的domain / type 一致
TODO:属性个数一致?
连接

Semijoin
半连接:只会将满足连接条件的元组,保留来自指定关系的属性,也就是在theta join的结果取projection
- 比如左半连接,将会得到左侧关系的匹配元组
null 表示值处于unknown状态 或者 不存在
Outer join
外连接:在自然连接的基础上,保留特定关系不匹配的元组
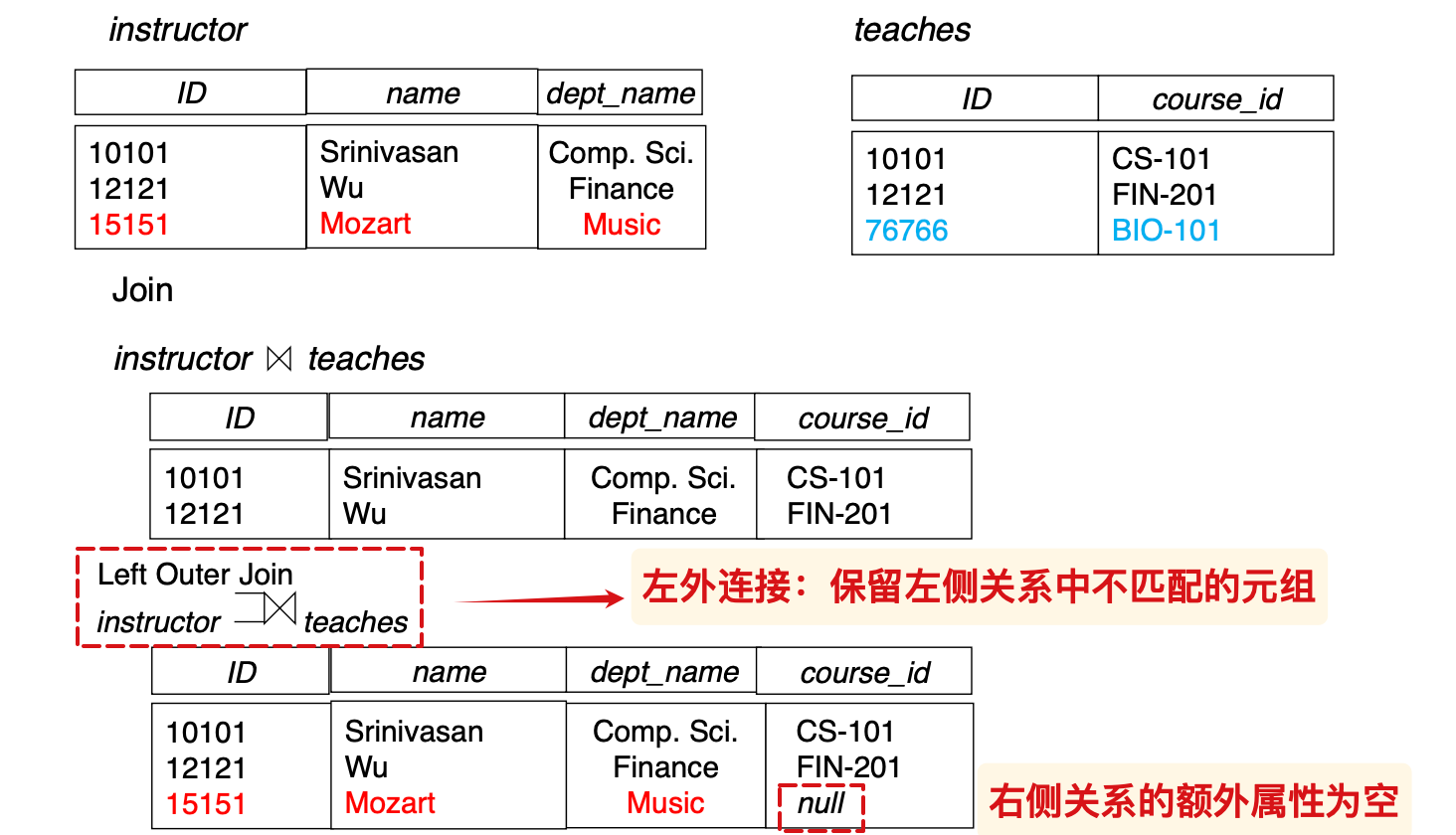
使用joins组合外连接

numeric(3,1) 总共3位,且小数点后1位
numeric 是 fixed point number, 与浮点数相区分
float(n) 表示至少有n位
primary key declaration on an attribute automatically ensures not null
主键自动具有非空的约束条件
unique
使用 unique来测试子查询是否含有多个元组
当子查询返回的元组个数是0或者1时,
简单的例子:

with
简单的例子:

关键词:
with和as
user-defined types
type和 domain都是用于自定义的数据类型, 二者十分相似. 区别在于: 后者可以声明约束 constraints.
Type
语法
1
2
3
4
5create type type_name
as data_type
[ (precision, scale) ]
[ not null ]
[ final | instantiable | abstract ];final | instantiable | abstract:用于指定类型的继承属性。
final:表示该类型不能被继承。instantiable:表示可以创建该类型的实例。abstract:表示该类型是抽象的,不能创建实例。
e.g.
1
2
3
4
5
6
7
8
9create type dollars
as numeric(12, 2)
final;
create table department (
dept_name varchar(20),
building varchar(15),
budget dollars
);
Domain
当某些列需要限制其取值范围, 也就是具有一定的约束条件时, 如果每次创建类似的列都重复书写, 工作量较大.
domain可以理解为对数据类型的扩展定义,它允许我们创建自定义的数据类型,并且可以为其指定约束条件。使用 domain 可以确保数据的一致性,
- 基本语法
1 | CREATE DOMAIN 域名 数据类型 |
- e.g.
1 | -- 创建一个表示年龄的域 |
Large-Object Types
MySQL BLOB datatypes:
- TinyBlob : 0 ~ 255 bytes.
- Blob: 0 ~ 64K bytes.
- MediumBlob : 0 ~ 16M bytes.
- LargeBlob : 0 ~ 4G bytes.
上限以
的规模递增
候选键CK可以为null,但是主键PK不能为空
因此,unique构成组成的属性集合可以称为构成了一组超键,但是不能称为CK,因为CK可以为空
assertion
e.g.
1 | create assertion credits_constaint check ( |
使用下面的命令来阻止数据库对SQL的隐式commit:
1 | set autocommit = 0 |
授权
四种权限:增删改查
- insert不允许修改现有的数据;
- update不允许删除现有的数据
五种修改数据库范式的权限:

范式的创建、修改、删除,以及index和view相关的操作
Authorization
- 授予权限:
1 | grant <privilege_list> |
这里的 <user_list>既可以是具体的用户名,也可以是关键字 PUBLIC(表示授权给所有用户)。
特别地,当我们需要允许用户具有转授权的能力时,可以在授权语句末尾添加 WITH GRANT OPTION子句。

- 权限回收:
1 | revoke <privilege_list> |
- 其中
RESTRICT表示仅回收直接授予的权限,而CASCADE则会同时回收该用户转授给其他用户的权限(级
- 可以在权限列表中声明
all表示回收所有的特权;- 可以在用户列表声明
public表示回收的范围是正常访问的普通成员, 但是不会回收指定的成员的特权
- 如果同一个用户被不同的授权者先后授予了2次相同的权限, 那么一次的回收权限之后, ta的权限可能依旧存在.
- 权限的依赖性: 如果回收的权限会导致具有依赖关系的权限的失效, 那么涉及的权限也会被回收:
创建外键约束的权限
1 | grant reference (dept_name) |
数据库设计的流程
- requirement specification
- conceptual-design: E-R diagram
- logical-design:logical schema
- physical-design: physical schema
设计范式的时候,主要避免两个问题:
- redundancy
- incompleteness
entity: an object that exists and is distinguishable from other objects
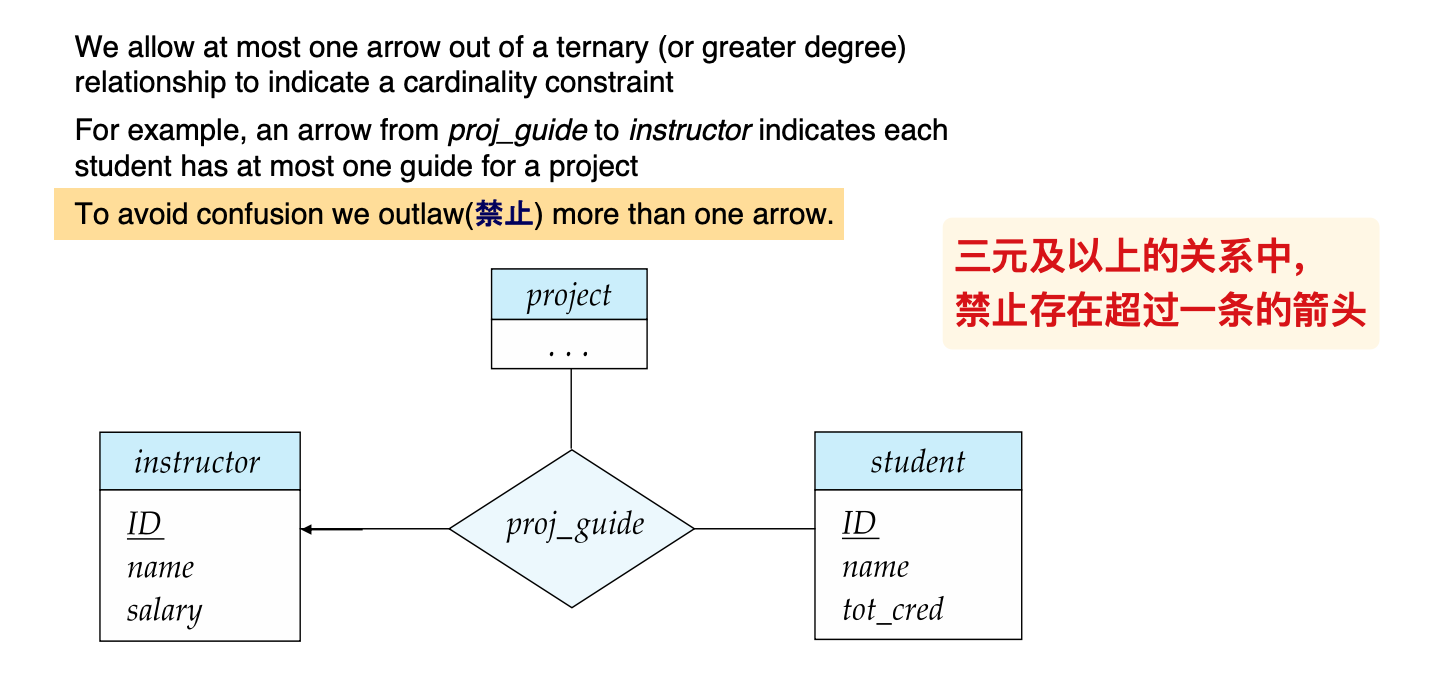
三元关系与箭头
Armstrong’s

以及对应的推论:

按照BCNF分解:
- 一定是无损分解
- 但不一定是满足依赖保留的
按照3NF分解,可以同时满足上面两条
MVD
定义

相关定理与4NF
- 任何函数依赖一定也是多值依赖
- D的闭包D+是逻辑上由D隐含的所有功能和多值依赖项的集合;
- 如果一个关系范式满足下面的要求,就称为满足4NF,对于函数和多值依赖D,如果其D+中的所有多值依赖都只存在下面两种情况之一;
- 平凡的(右侧包含在左侧属性,或者二者的并集是R)
- 左侧属性是R的超键
4NF类似于普通关系的BCNF
物理存储系统
存储级别
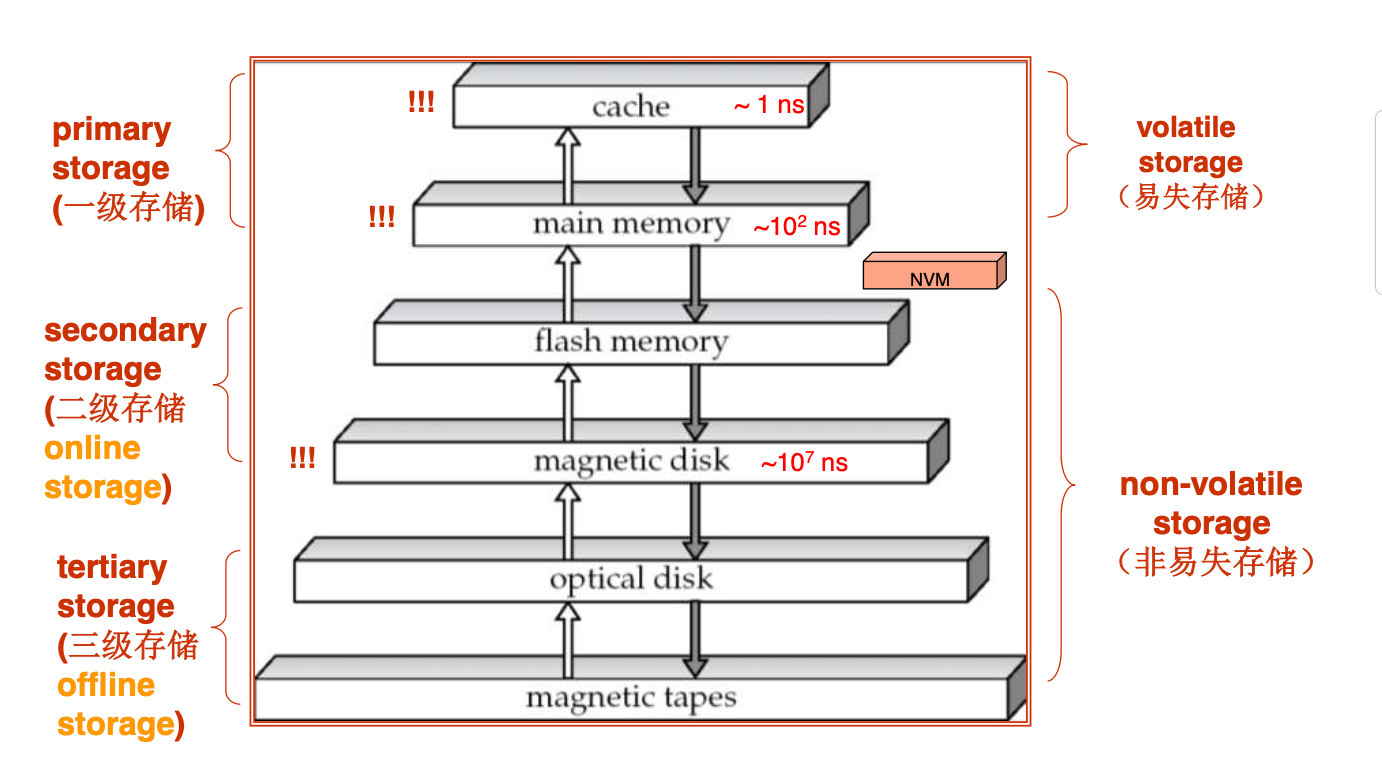
访问时间 = 寻道时间 + 旋转延迟
disk-block访问的优化:
- buffering
- prefetch
- disk-arm-scheduling:使用算法重排block的请求
- 非易失性写缓存
- non-volatile RAM: battery backed up RAM or flash memory
- log disk 日志磁盘
Flash storage
NAND flash
- page-at-a-time read
- 在erased之前 一个page只能被write一次
SSD:splid state disk
通过flash translation table将逻辑页地址转换成物理页地址
在分槽页中,记录指针不是直接指向记录,而是指向对应entry的header
文件中记录的组织形式:
- heap:记录可以存放在文件的任意位置;
- sequential:根据search-key线性存储记录
- hashing:利用哈希函数计算search-key,然后存储到对应的block中
- multitable clustering file organization:将不同关系的记录存放在同一个文件中
- 可以为同一个关系的记录之间增加指针,形成pointer chains 指针链
- table partitioning:将一个关系中的记录分成更小的关系,分别存储
- 相当于上一种形式的对立
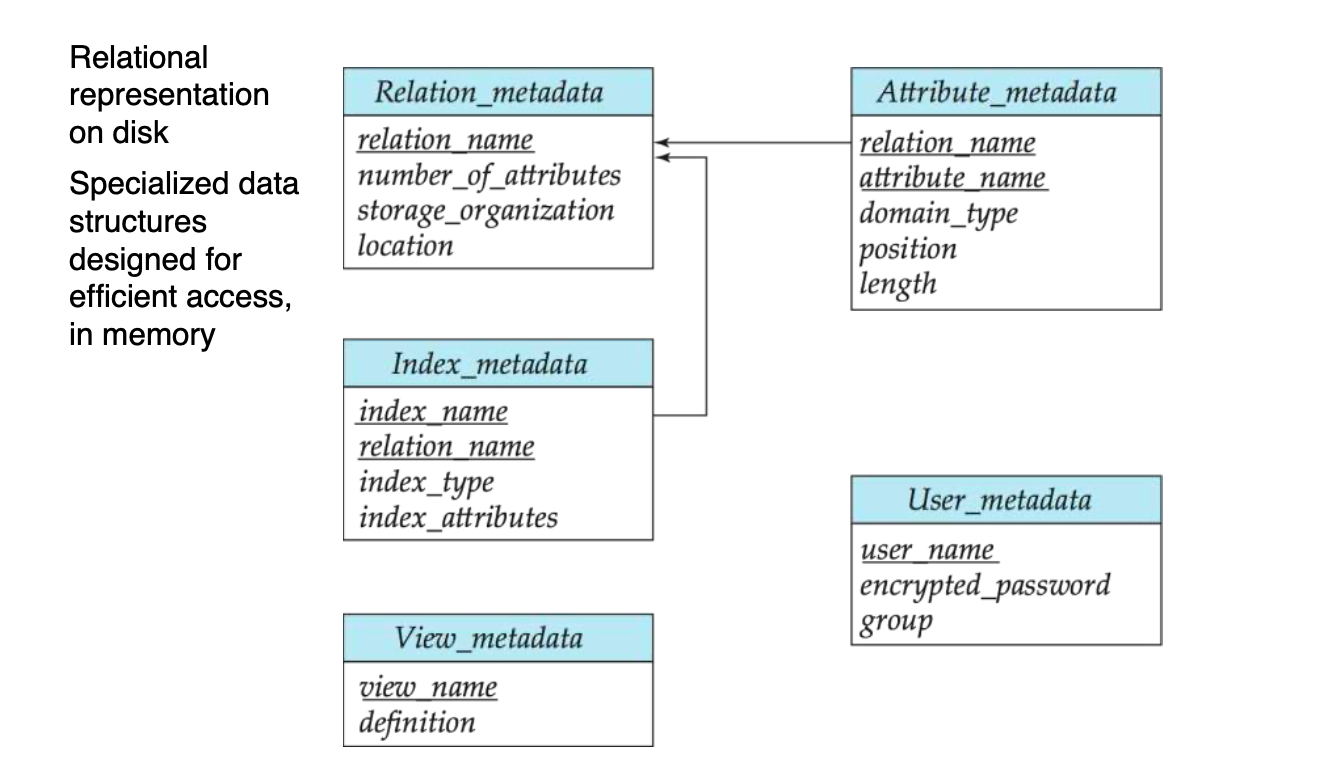
- data dictionary storage
- 也称为system catalog
- 存储metadata
Buffer-Replacement Policies
- LRU
- Toss-immediate strategy:只要一个block的最后一个元组的数据被处理结束,就释放这个block
- MRU:刚处理结束的block是最可能被替换的对象
- clock:
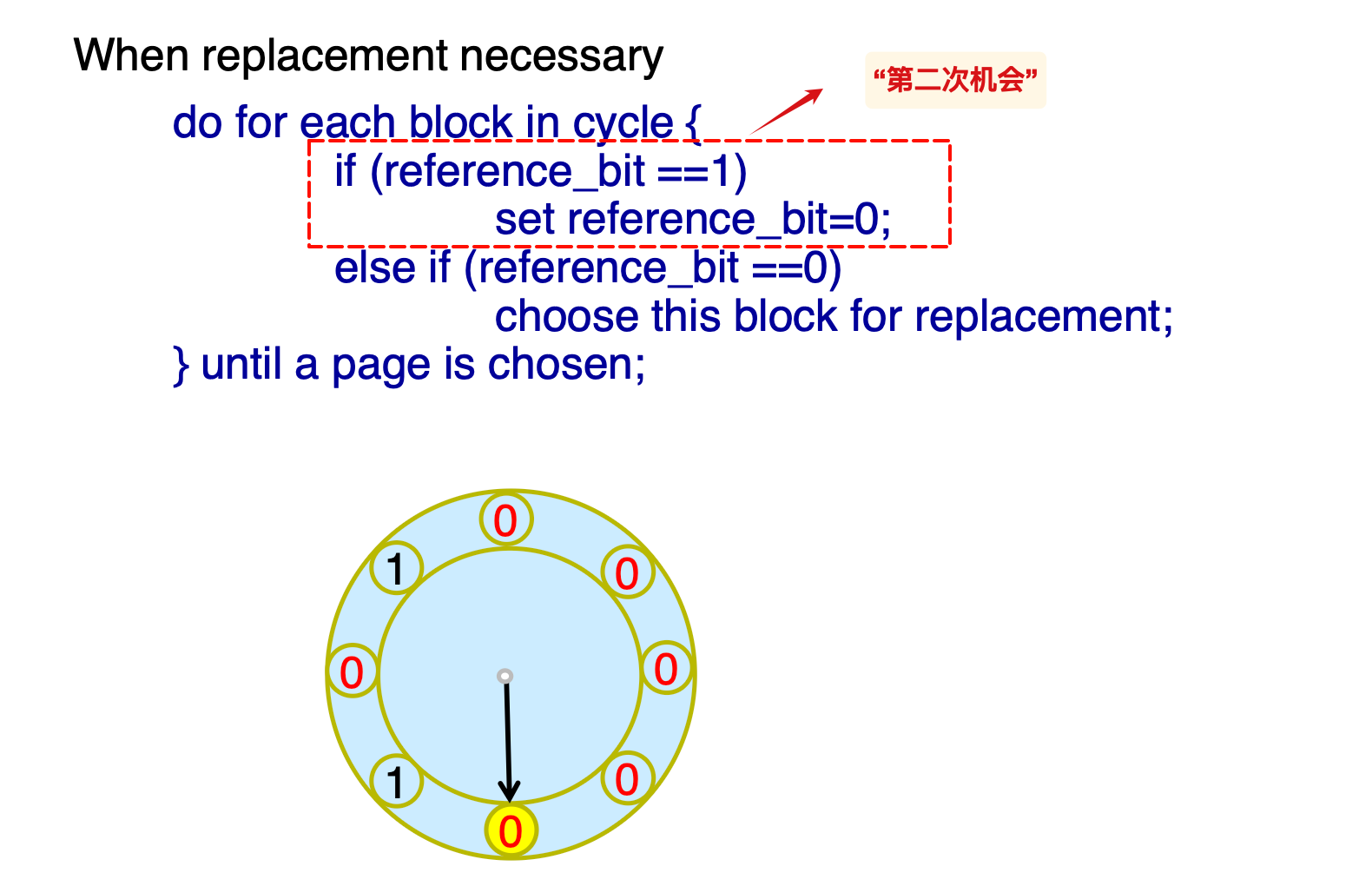
Column-Oriented Storage
也被称为 columnar representation

列:决策支持;
行:事务处理
ORC 优化行列存储
- Apache ORC 和 Apache Parquet
- 流行处理big-data的应用
索引顺序文件:根据主索引排序的有序文件
稠密索引——对建立索引的属性,每一个值都有自己的指针;
- 稀疏索引:只有部分search-key的索引,因此要求记录必须按照搜索键来排序
如果主索引无法存储在memory中,需要将disk上的主索引看成线性文件,建立外层的稀疏索引
B+复杂度与占用率

针对写密集型的B+树的策略:
- LSM tree
- buffer tree
- 更少的查询开销

bitmap indices:
- 取属性的值域的大小作为行数
- 有记录的个数那么多列,如果对应位置的属性匹配,bit就是1
index on flash
todo:ch14-51
ppt的A4‘有问题,参考书本的定义
如果查询的比较条件是 <= ,就不要使用index,直接使用线性查找

merge成本最小化
混合的归并合并
- 使用前提:
- 第一个关系是有序的;
- 第二个关系在连接属性上具有B+树的index,方便根据属性查找
- 流程概述:
- 顺序扫描第一个关系;
- 对于第一个关系中的每一个元组,利用连接属性在第二个属性中使用索引查找得到对应的叶子节点,然后将第一个关系的元组合并到叶子节点中
- 此时第二个关系的B+树叶子节点具有实际物理地址和第一个关系的元组,将其按照自身的物理地址排序
- 然后,我们得到按照地址排序的叶子节点,可以顺序扫描,然后构造合并结果(用第二个关系的元组来替代物理地址)
- 上述流程的关键就在于,通过先根据物理地址排序,然后顺序扫描,降低了随机访问导致的大量的寻道时间

估计交集的成本时:
- 如果连接属性是其中的外键-主键关系,成本是确定的——引用关系的元组数;
- 如果是平凡的关系,那么就利用V计算,取最后估计结果较小(V较大的)

外连接的成本估计 = 自然连接的结果+对应属性的元组个数
cost-based optimizer
为每个操作选择cheapest的算法(贪心)可能不会产生最优的整体效果,比如:
- 合并连接可能比哈希连接成本更高,但是有序的输出可能为外层的算法提供便利;
- 嵌套循环可以为流水线提供机会
n个关系连接时,具有
我们不需要一次性对所有的关系采取套用上述的公式,可以采取动态规划的思想:
从较小的子集开始取用,计算小规模的不同关系的所有连接成本,存储在数组中,在较大规模的计算中直接取用即可
best join tree

复杂度:
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 动态规划 | ||
| only left-deep trees |
启发式优化
策略
- Perform selection early(reduces the number of tuples)
- Perform projection early(reduces the number of attributes)
- Perform most restrictive selection and join operations (i.e. with smallest result size) before other similar operations.
- Perform left-deep join order
物化视图的增量更新
对于选择, join可以直接在原来的结果上:
- insert ==> 并集;
- delete ==> 差
- 对于avg, max, min等统计属性, 采取之前的中间结果来辅助实现增量更新.
- 方差也可以用增量更新来维护.
因此, 只需要维护各个元素的和, 平方和 以及计数 n, 就可以实现快速的增量更新.
并发控制
2PL
两阶段锁协议 2PL 可以保证冲突可序列化
- 将事务的执行顺序按照lock points排序
- 但是冲突可序列化的调度不一定满足2PL协议,也就是说2PL不是冲突可序列化的必要条件
- 不保证排除死锁
严格2PL:事务必须保持自身的exclusive locks直到其commits / aborts
- 确保可恢复性
- 避免了级联回滚
强2PL(rigorous):事务必须保持自身的所有lock,直到其commits / aborts
- 可以按照事务提交的顺序来构建序列
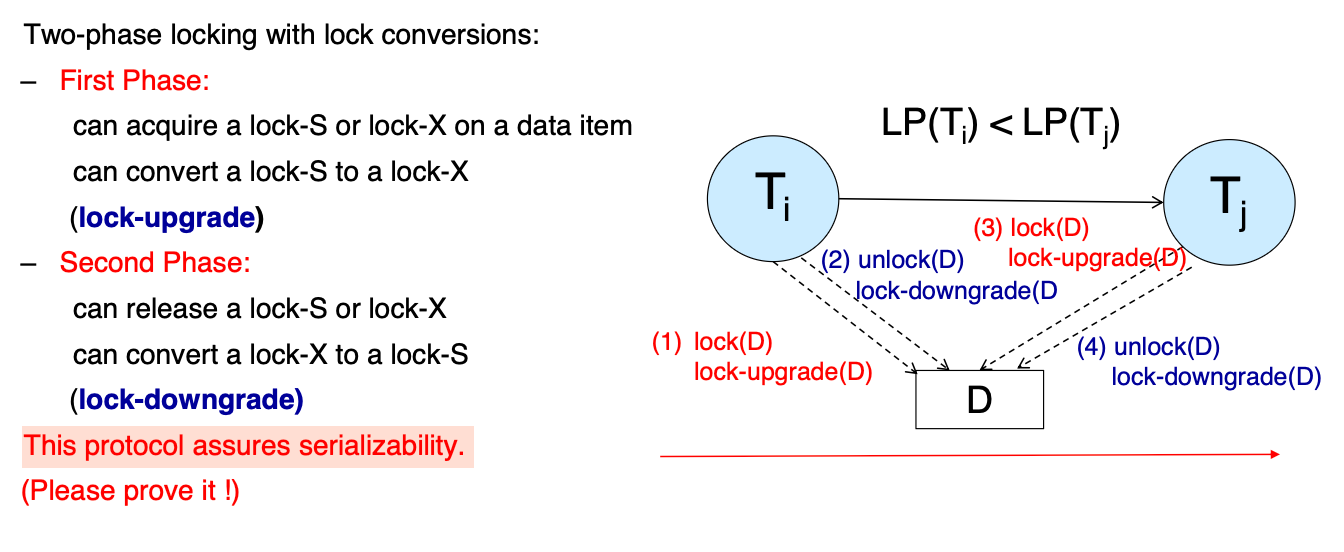
Lock Conversions
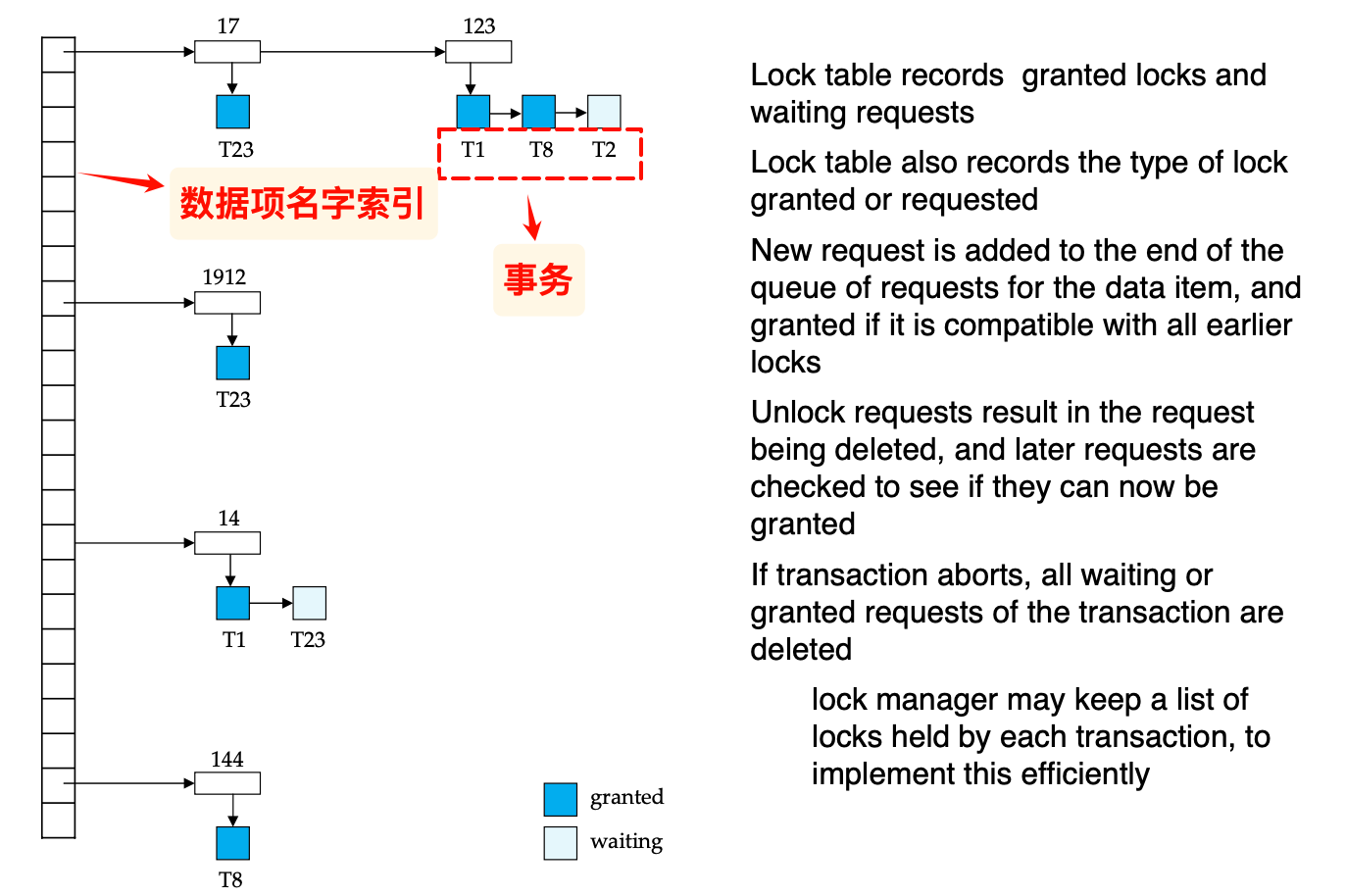
Lock table
usually implemented as an in-memory hash table indexed on the name of the data item being locked
- 新的请求添加到队列的末尾,并且检查是否与先前的lock相同,如果相同就grant
- 请求删除的时候同时unlock 对应的requests,并检查pending的lock是否可以被granted
Tree Protocol
是图协议的一种,适用于对数据访问的次序具有偏序结构理解的情况
中译中:了解访问特定的数据项之前必须经过的中间节点
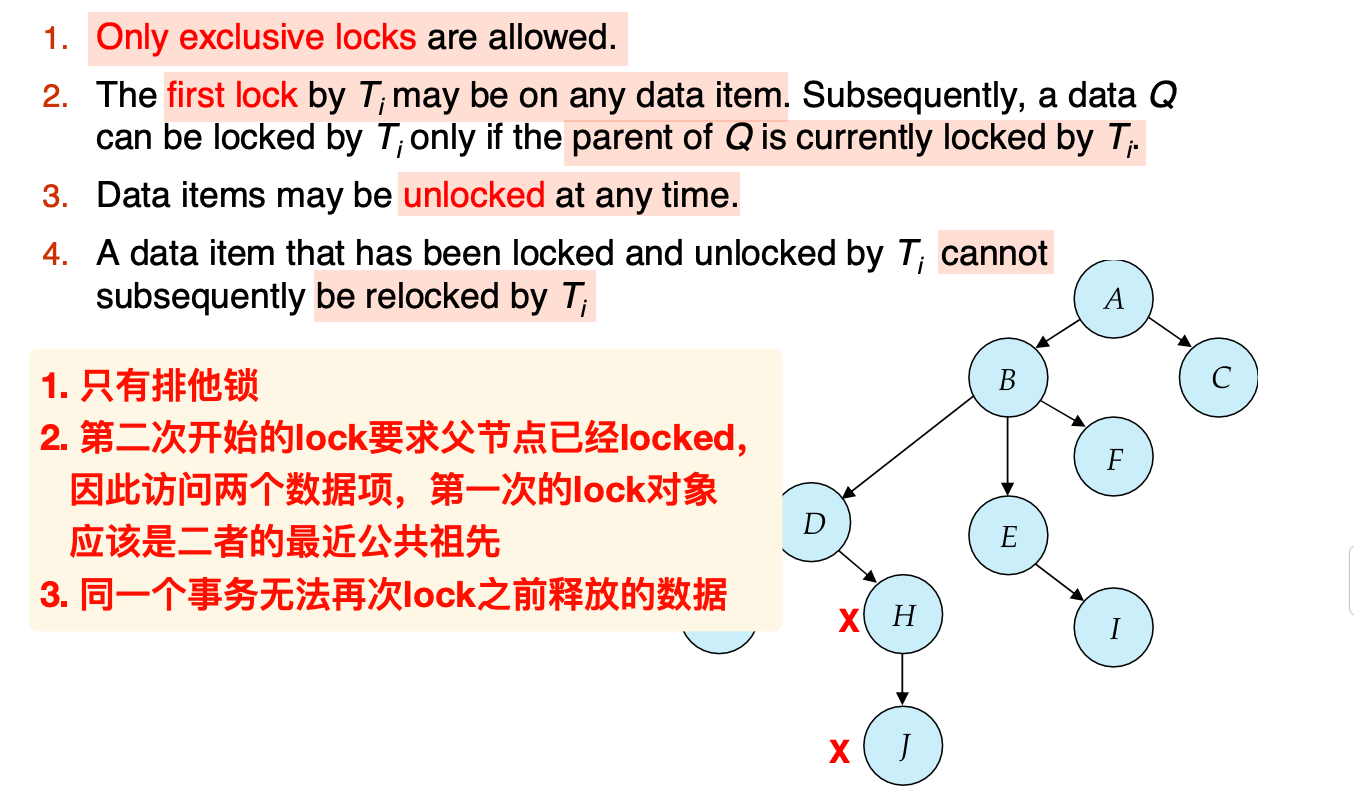
特点:
- 树协议可以保证冲突可序列化并排除死锁 (deadlock-free)
- 避免了回滚
- 缺点:
- 不能保证无级联和可恢复性
- 可能 lock more data items than needed, 从而降低了并行性,同时提高了额外的等待时间
Schedules not possible under two-phase locking are possible under tree protocol, and vice versa.
Granularity Hierarchy
从高到低,以整个数据库系统为根节点,分别划分为不同大小的区域,直到叶子节点包含单个记录的信息
为了在高层级快速判断底层节点是否被加了 S / X锁引入 intention locks:

如果直接加X-lock,表示可以直接修改内部的节点
对应的相容矩阵:

X与任意锁都不相容;除了IS和X,都只跟自己相容;IS与X之外的锁相容
对于插入和删除记录,如果只是在对应的记录上加锁,可能导致幽灵现象和死锁问题
- 可以直接在表层级加锁,但是降低了并行性
- 可以引入谓词锁,来准确判断影响的记录范围,但是在实现上比较困难
- 另一种更好的解决方法是:Index Locking Protocol
Index Locking Protocol

可以避免幽灵现象的发生
一个例子:
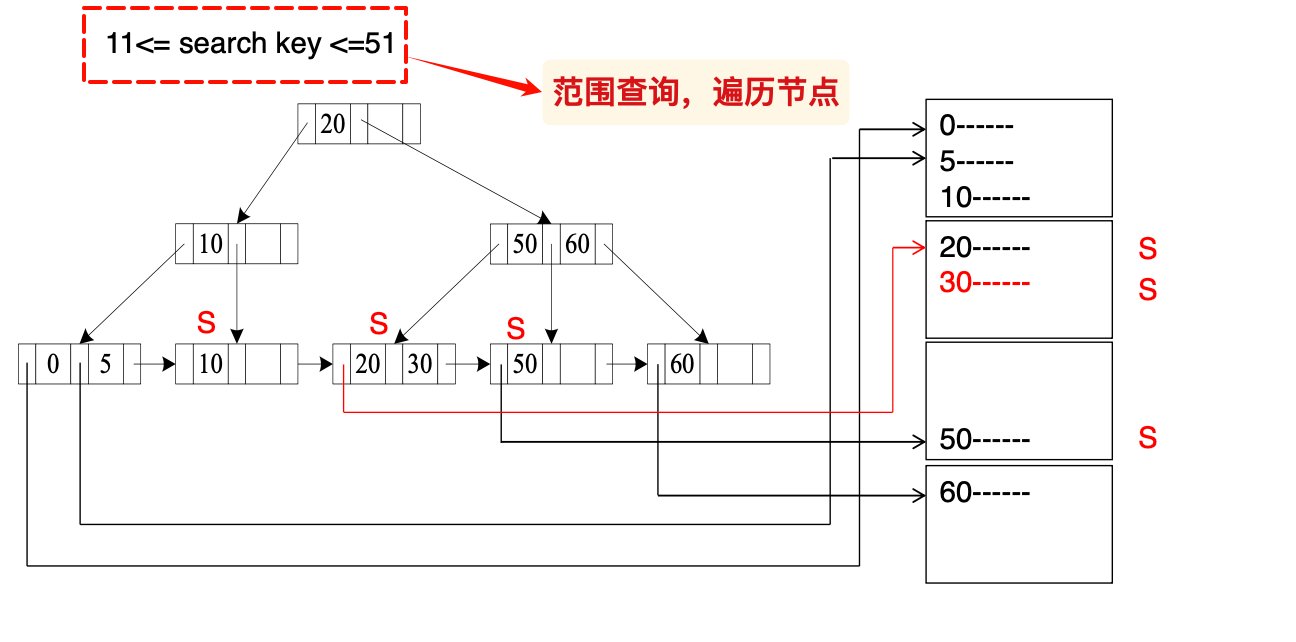
注意范围查询,导致10所在的叶子节点也具有了S-lock
上述的策略会将entire leaf给lock,为了提高并行性,我们可以针对某个key来lock,同时为了确保可以发现潜在的幽灵现象,需要引入一定的限制条件,这就是:Next-Key Locking
Next-Key Locking

TODO
B+-height

SOLUTION:
此处的height确实是从1开始的,比如计算max时前面的4个4是n, 最后一个是叶子层的叶子块内部的n-1,所以高度为h, 计算size时存在的因数个数也是h
- 标题: 数据库系统复习
- 作者: ffy
- 创建于 : 2025-06-21 19:03:07
- 更新于 : 2025-06-29 10:00:42
- 链接: https://ffy6511.github.io/2025/06/21/课程笔记/数据库复习/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。


