
计算机体系结构复习
任课老师:何水兵
知识点梳理
CH1
可靠性
- availability = MTTF / MTBF
- FIT:faliure in time = 1 / MTTF
计算系统整体的MTTF时,我们可以优先计算FIT(各个组件的rate相加),然后求倒数
MIPS
millions of instructions per second
Performance
performance是执行时间的倒数
不同的性能比较策略

几何平均就是将各个程序的执行时间相乘然后开根号,作为平均的执行时间;
depends on which machine is the reference:在不清楚加权算法中的权值情况时,采取参照的方法计算平均值,类似于加权的效果,但是结果与选择的参照对象相关,因此说~
几何平均:

流水线相关
可以一定程度上允许结构冲突:
- 为了减少cost和减少单元的latency
throughput
The throughput of a CPU pipeline is the number of instructions completed per second
CPU流水线的吞吐量指的就是每秒执行的指令数
how to stall
- 设计stall控制单元,检测是否存在冲突需要stall
- 如果需要stall,就disable writing PC and IF/ID latch,并且插入一个nop指令到ID/EX,禁止写回寄存器和写入MEM
double bump
如果在一个cc内允许 write-then-read,就可以只插入两条nop:
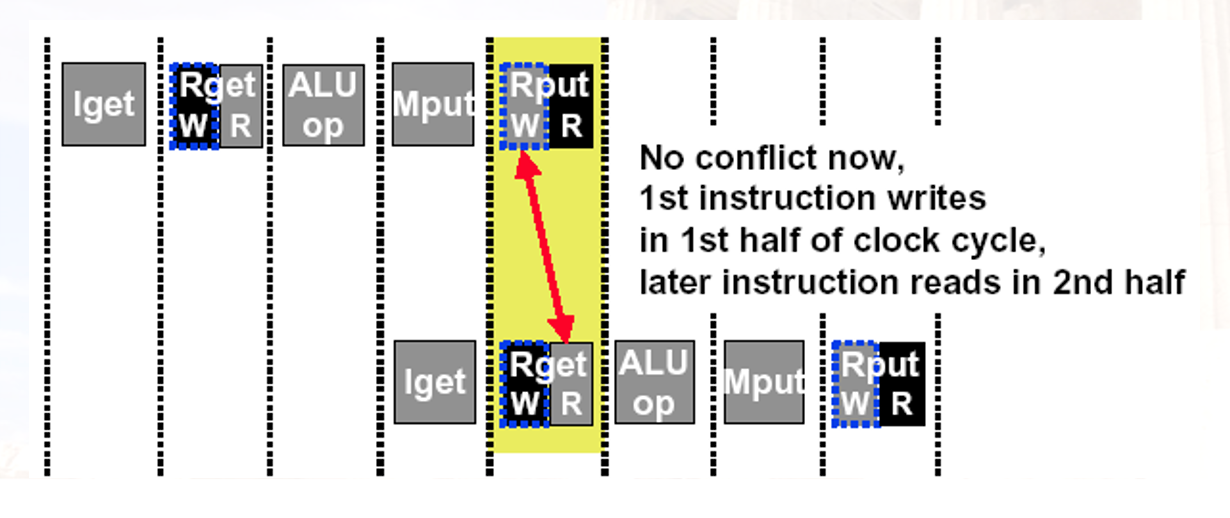
跳转指令
∆ = 目标地址 - 跳转指令的下一条指令的地址!
因为在取出指令后PC+4就生效了;
与汇编指令具有异曲同工之妙

同时注意,是在MEM阶段而非EX阶段写回PC寄存器,在跳转指令的WB阶段开始取址
总共stall了3个cc
对应的简单问题:

为了解决上述的stall损失,我们可以考虑在EX阶段前递,或者在ID阶段增加硬件单元。
另外的可行办法是延迟槽技术:
- 因为跳转指令在ID阶段才确定,此时IF已经取址了。我们将一定会执行的指令(无论跳转是否发生)放置在条件跳转指令的下一条,避免这条(组)指令的浪费
- 延迟槽中的指令应当由编译器选择合适的指令(组)
移位寄存器
为了解决写端口的冲突,直接增加写端口是不经济的。
我们考虑一种检测矛盾并实现序列化写操作的技术——使用移位寄存器:

在ID阶段分析指令之后,如果与已经发射(此处应该指的是应该开始执行?)的指令存在写端口的冲突(利用移位寄存器判断),就stall这条指令
如果指令需要写回,利用一个移位寄存器,设置与当前指令将要写回所需的cc相等的值,作为移位寄存器位数的1.每个cc将对应的移位寄存器右移。
数据冲突
- RAW:true dependance,因为无法通过寄存器重命名或者指令重排来优化
- WAW:output dependance
- WAR:anti-dependance,因为和RAW是相反的
CH2 存储器层级
block identification
- index 用于选中cache的set / cache line
- index bits =
- index bits =
- offset:用于选择block内部的data
- offset size =
- offset size =
- tag:用于比较block是否匹配
- bits: 地址size - index size - offset size
一个简单的直接映射的计算例子:
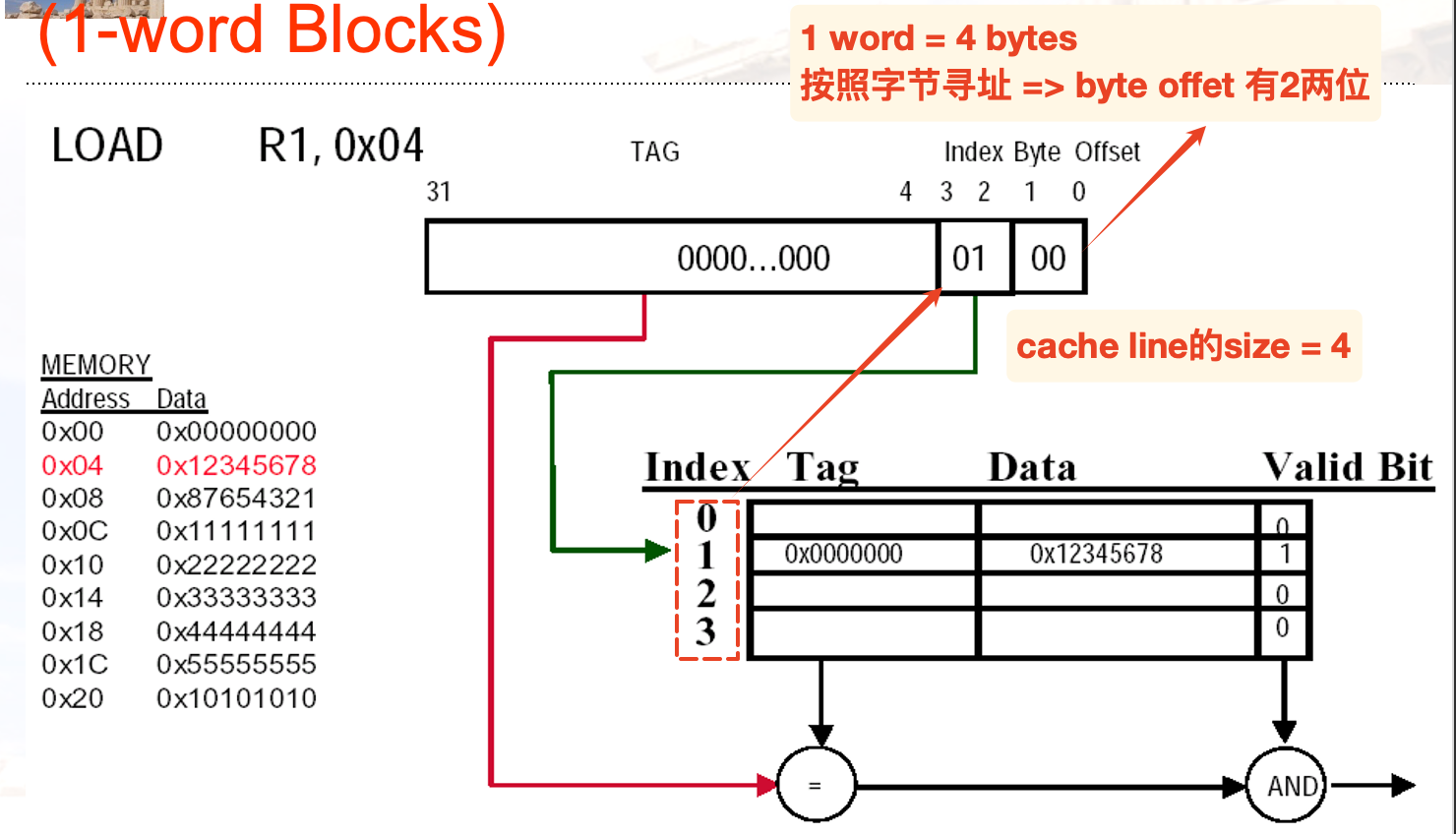
- 地址总位数可能由memory size间接给出:e.g. Memory-size = 4G =
, 得到一共有32位
write strategy
一般来说:
- 写回策略 + write allocate
- 写穿策略 + write around:发生write miss的时候,只会写入到内存
一个简单的例子:

当发生了read miss的时候,将mem[200]加载到cache,下一次的写将命中
Cache performance
Memory stall
CPU Execution time = (CPU clock cycles + Memory stall cycles) x Clock cycle time
- 其中后者可以如此计算:
- 注意判断是否需要将data和ins.的mem区分
一个简单的例子:

- 其中后者可以如此计算:

AMAT
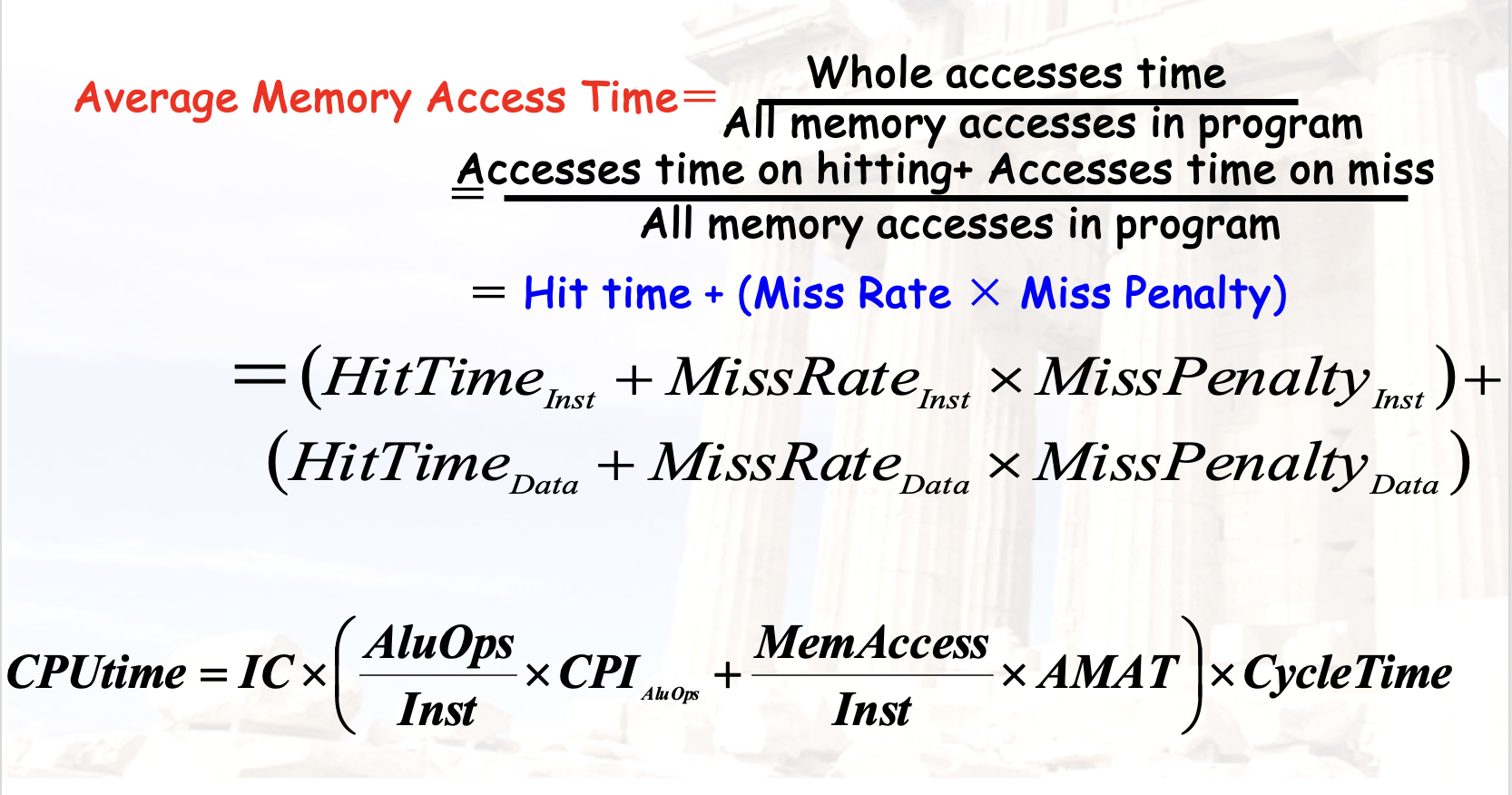
AMAT也就是: Average memory access time.
所以可以用来计算 real CPI= Ideal CPI + Average stalls per instruction , 其中后者根据:
计算得到, 且 HitTime为理想的CPI, access times是每条指令平均访问memory的次数 = MPI , e.g. 有30%的数据访存指令, 对应了1.3.(考虑指令cache的1 on unified cache)
一个简单的例子——AMAT按照data和ins加权计算:

补充:
- MPI(memory reference per instruction)=1.5 , 也就是指令对mem的平均访问次数.
- 注意AMAT的计算涉及了hit time,unified cache的hit time可能比split cache的大
- 无特别说明的情况下,hit time = Ideal CPI
Split & Unified
- miss rate的计算:

表格中给出的数据是miss相关的估计,实际上的MPI可能由题目进一步给出,因为不同的程序对应的访存比例可能不同,根据实际情况计算
Improve cache performance
减少hit时间 4’
small and simple caches
- 更少的硬件支持;直接映射的速度更快
avoiding address translation
- 使用TLB作为page table的cache,Virtual indexed, Physically tagged
way prediction
- 在cache中采取extra bits预测way,如果预测正确只需要1cc;否则需要额外的cc改变预测位
trace caches
- trace:动态指令序列,主要为
branch设计 - 将branch在内的指令打包放入trace cache,由于大部分时间,分支跳转后要指令的指令序列是相同的,因此我们可以直接从trace cache中取用
- trace:动态指令序列,主要为
增加cache的bandwidth 3‘
- pipelined cache access
- 顾名思义,将cache的访问流水线化
- multibanked caches
- 将cache划分为几个不同的区域,从而允许同时的访问
- non-blocking caches
- 针对 hit under miss 的情况设计,允许CPU在miss之后继续执行指令,避免陷入阻塞block
减少miss penalty 4’
- multilevel caches
- 多级cache带来的概念:local miss rate(当前level的缺失率) 与 global miss rate(与上层的cache相关)
- critical word first
- 在block中找到需要的word后就快速启动,后续指令的执行和block的剩余内容的搬运并行执行,因此通常用于block的size较大的情况
- 又称为 wrapped fetch 与 requested word first
- read miss prior to writes
- 在写回策略下, 如果发生了
read miss, 需要从主存中读取对应的块并写入cache. 可以直接取出数据并开始执行指令, 将待写的数据放入buffer.
- 在写回策略下, 如果发生了
- merging write buffers
- 多次的写合并到一次的操作, 特别是写的地址是相同的时候,显著降低了penalty
- victim caches
- 在相邻的cache层级之间增设牺牲缓存
- 发生一次
miss之后并不直接将其踢出cache, 而是放入~
降低miss rate 4’
控制变量分析
- larger block size
- 降低了强制miss rate
- 但是增大了miss penalty,以及发生冲突miss的可能(block的数量减少)
- large cache size
- 经验法则: 翻倍的cache容量, 带来降低25%的缺失率.
- 降低了容量miss
- 但是增大了hit time和cost
- higher associativity
- 经验法则: 一个大小为N的直接映射缓存 , 与一个大小为N/2的2路组相联 缓存具有相同的未命中率.
- 8-way比较理想。更大的组关联度导致比较时间的增加,从而可能导致时钟周期的增大/周期数的增加
- compiler optimization
- 在不改变硬件的情况下, 使用编译器重排指令的序列
- 数组合并
- 循环交换:改变循环的嵌套顺序
- 循环融合
- blocking策略
- way prediction and Pseudo-Associative Cache
- 路预测的技术与之前提到的相同,用一个预测位来预测
- 伪关联缓存:divide cache,然后在miss之后查看当前cache的剩余部分
- 如果此时命中,称为 pseudo-hit,时间介于hit 与 miss penalty之间
3C回顾:
- Compulsory: 冷启动,又称为强制miss;
- Capacity: 缓存的空间不足导致的 miss. 发生在全关联当中.
- Conflict(collision): set associative or direct mapped当中发生.
主要关注冲突miss和强制miss的优化
通过流水线降低miss penalty和rate 2’
- hardware prefetching
- 使CPU预先取用一部分的数据到特殊的缓存块当中, 从而降低了 冷启动的影响.
- 预取的结果放入
stream buffer,
- compiler prefetching
- 由编译器插入prefetch ins.来获取需要的数据
- 根据预取数据存放到寄存器还是cache,分为binding prefetch 和 non-binding prefetch
CH3
scoreboard
看一眼

流水线的阶段
- IF: 取指令
- IS: 以下条件同时满足时允许发射:
- FU空闲——避免结构冲突;
- 正在执行的指令,没有一条要写回的Rd与当前指令相同——避免了WAW冲突
- RO: 监视数据冲突,当且仅当两个源寄存器都准备好了,才读取
- EX: 在不同的FU中执行(MEM涵盖在整数的FU当中)
- WB:更新状态表之后的下一个cc可以RO
表的设计
- 指令状态表 Instruction Status Table
- 记录指令的状态,在哪个阶段
- 功能单元状态表 Functional Unit Status Table
busy:FU 是否空闲;op:FU 正在执行什么操作Vi,Vj,Vk:FU 的操作数对应着哪个寄存器Qj,Qk:FU 的操作数如果没准备好,应该从哪个 FU 读取Rj,Rk:操作数是否准备好,如果准备好了就填yes,然后在RO阶段读取之后立即改为NO- 率先执行的指令在WB的时候检查写入的寄存器是否在某个FU的ready-list中为
YES,表示等待另一个操作数准备好之后同时读取(还未读取)
- 率先执行的指令在WB的时候检查写入的寄存器是否在某个FU的ready-list中为
- 寄存器状态表 Register Status Table
- 如果某个寄存器的值正在被某个 FU 的操作生成,填入这个操作FU的编号
- 生成好了之后,填入实际值
显式重命名
通过设置更多的物理寄存器, 同时维护一个 free list.
- 每一条需要写寄存器的盒指令,均分配一个新的物理寄存器;
- 此时还需要记录原来的map(对应的物理寄存器),这是为了在发生中断/rollback的时候可以复原之前的映射关系;
- 当可以写回的时候,再将得到的值写回到逻辑寄存器,同时将锁定的物理寄存器 free up(加入到free list的末尾)
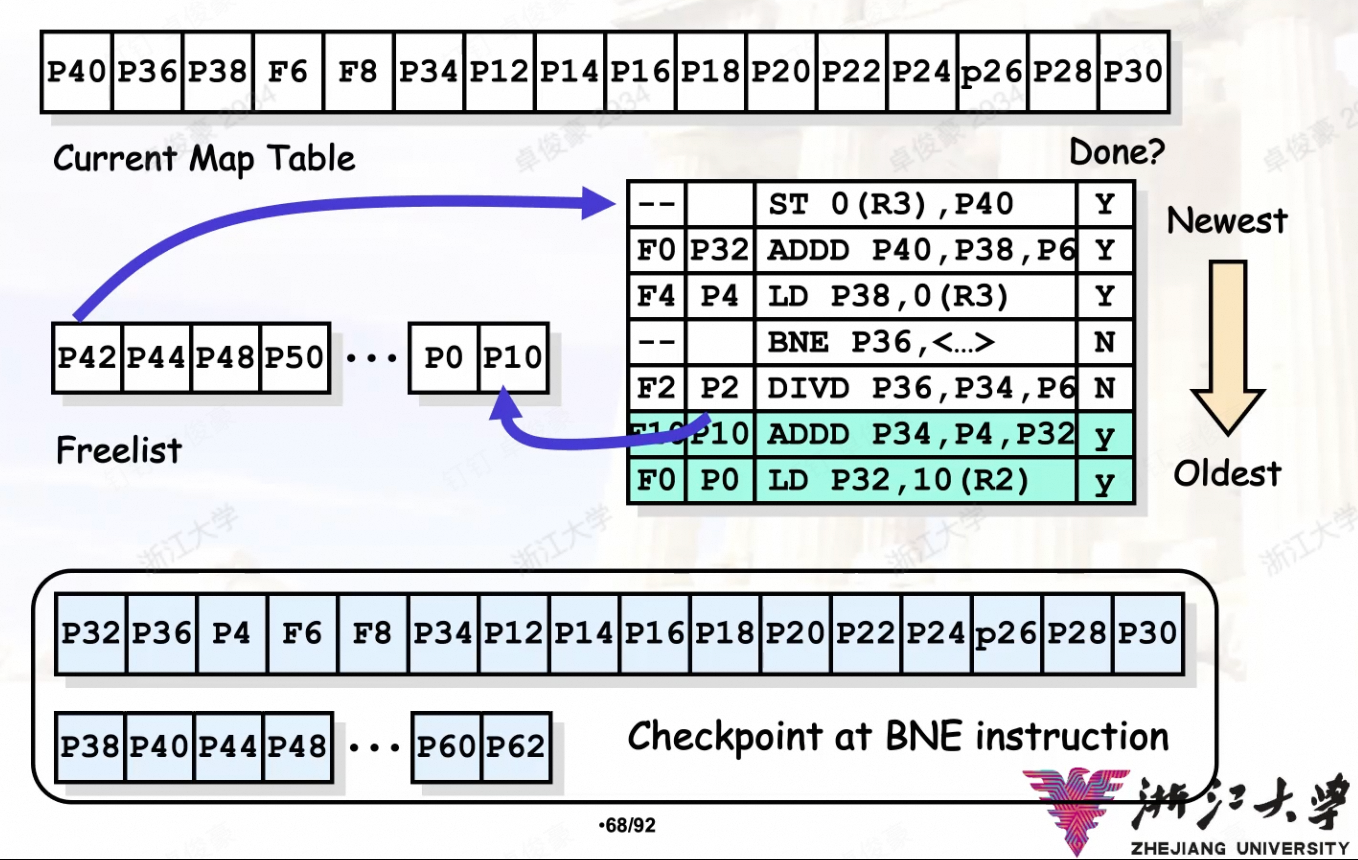
加入显式重命名之后的计分板阶段分析:

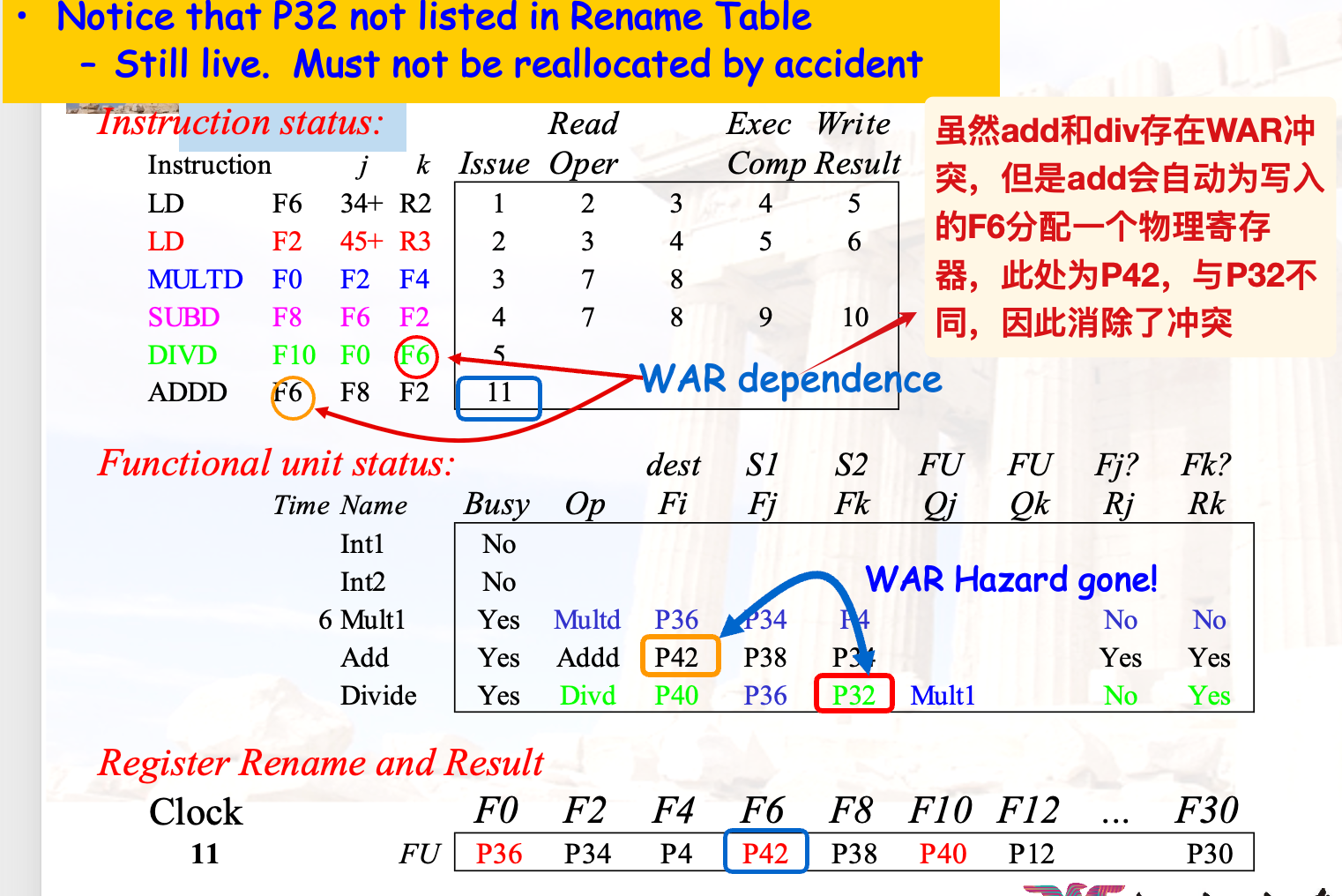
显式重命名消除冲突的示例:
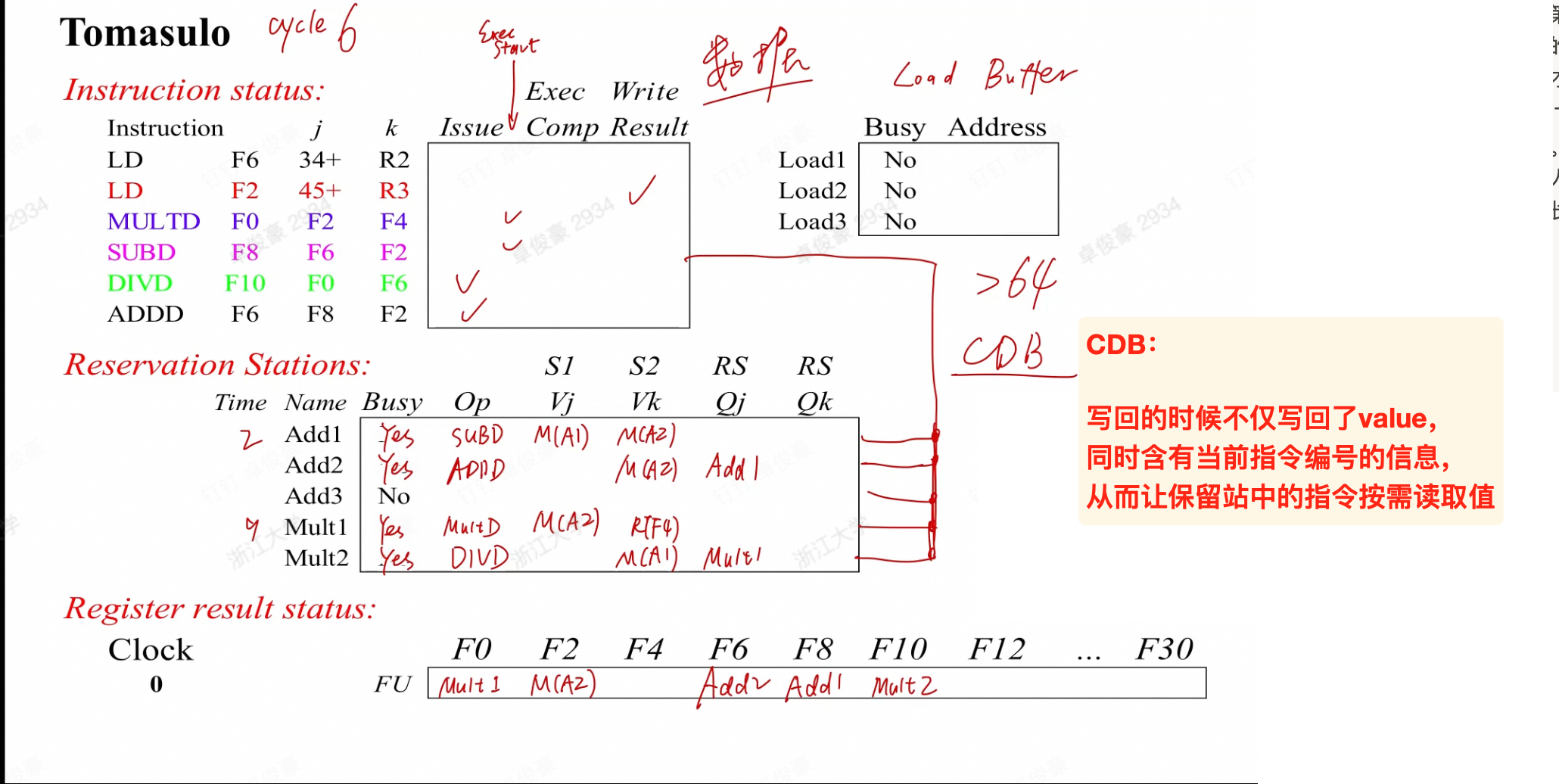
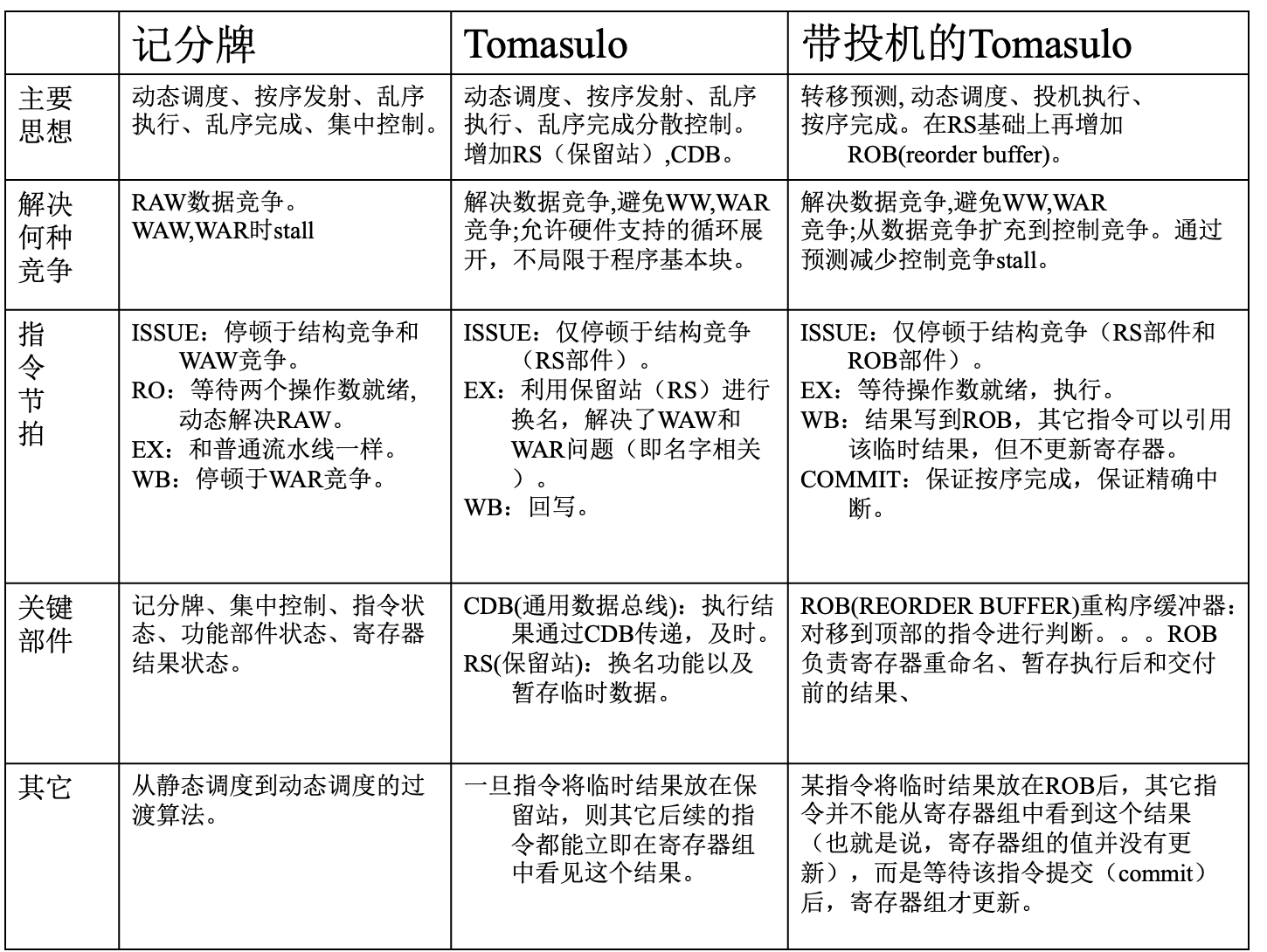
Tomasolo
算法的思想
- Scoreboard 算法的控制权全部在 Scoreboard 的三张表中
- Tomasulo 算法将 FU 的控制权交给 FU 自己,每个 FU 有自己的指令缓存
| IF | IS | EX | WB |
|---|
硬件设计
- 每个 FU 有一个 buffer,叫做保留站(reservation station)
busy:FU 是否空闲;op:FU 正在执行什么操作Vj,Vk:两个源寄存器对应的寄存器值(注意是值)Qj,Qk:两个源寄存器如果没准备好,应该从哪个 FU 读取- 此外还会记录 FU
<u>距离完成执行这条指令的剩余周期数</u>
- 内存也有自己的保留站,叫做 Load/Store Buffer
busy:这个位置是否有内存读写请求address:读写的地址
- 有一个 Register Status Table,和 Scoreboard 算法中的一样
- 有一个 Common Data Bus(CDB),负责将结果广播到所有的保留站和寄存器
- 将需要的数据从总线上直接取用, 而不用通过寄存器
- 因此传递的时候, 不仅传递值, 同时传递对应操作的编号
带投机的实现
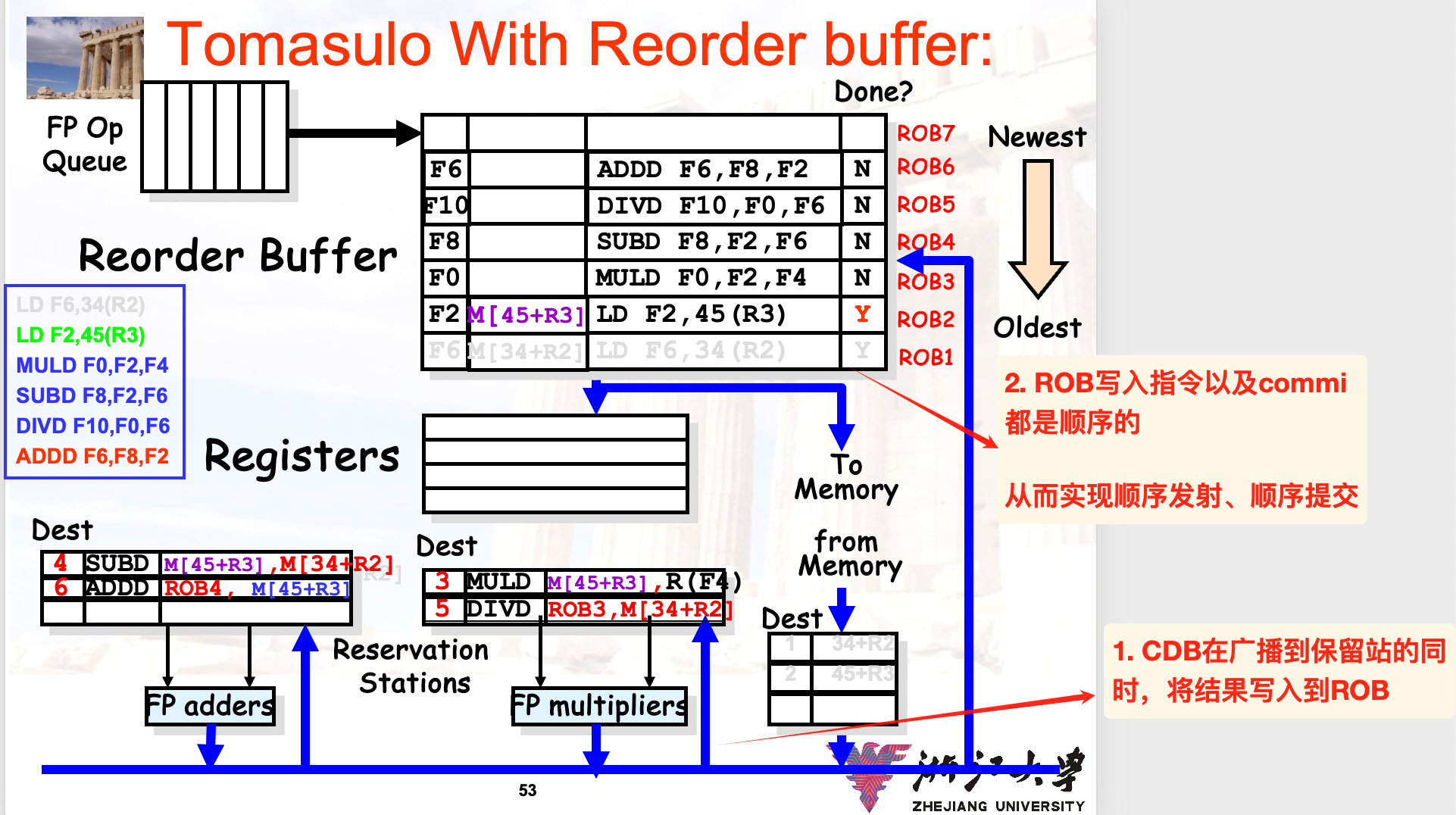
为了在遇到分支指令的时候避免stall,我们可以采取投机的方式——假设分支指令不会跳转,继续执行之后的指令
为了实现投机机制,我们需要一种在预测失败之后可以rollback的机制——新增Reorder buffer i.e. ROB
在之前的流程基础上,增加commit阶段,让CDB的结果先写入ROB,然后在ROB中实现顺序提交,如果头部指令是:
- 普通指令:将结果写回到寄存器和内存,然后从ROB中删除
- 分支指令,并且预测:
- 正确:当做普通指令,继续执行
- 错误:清空flush此时ROB中的所有指令
Notice:
- IS阶段需要将指令同时写到ROB中,因此只有当保留站和ROB都有空余的情况下,可以issue
- issue之后,可以从ROB和寄存器中读取操作数到保留站中
- 内存中的数据也可能存在RAW的冲突,因此在load的时候,需要从ROB中的store的地址相比较:

只有当我们明确知道load对应的内存地址与先前store指令的目标地址不冲突的时候,才执行load(向内存发送请求),否则stall
MEM的RAW与解决
参考的解决:

对应的例子:
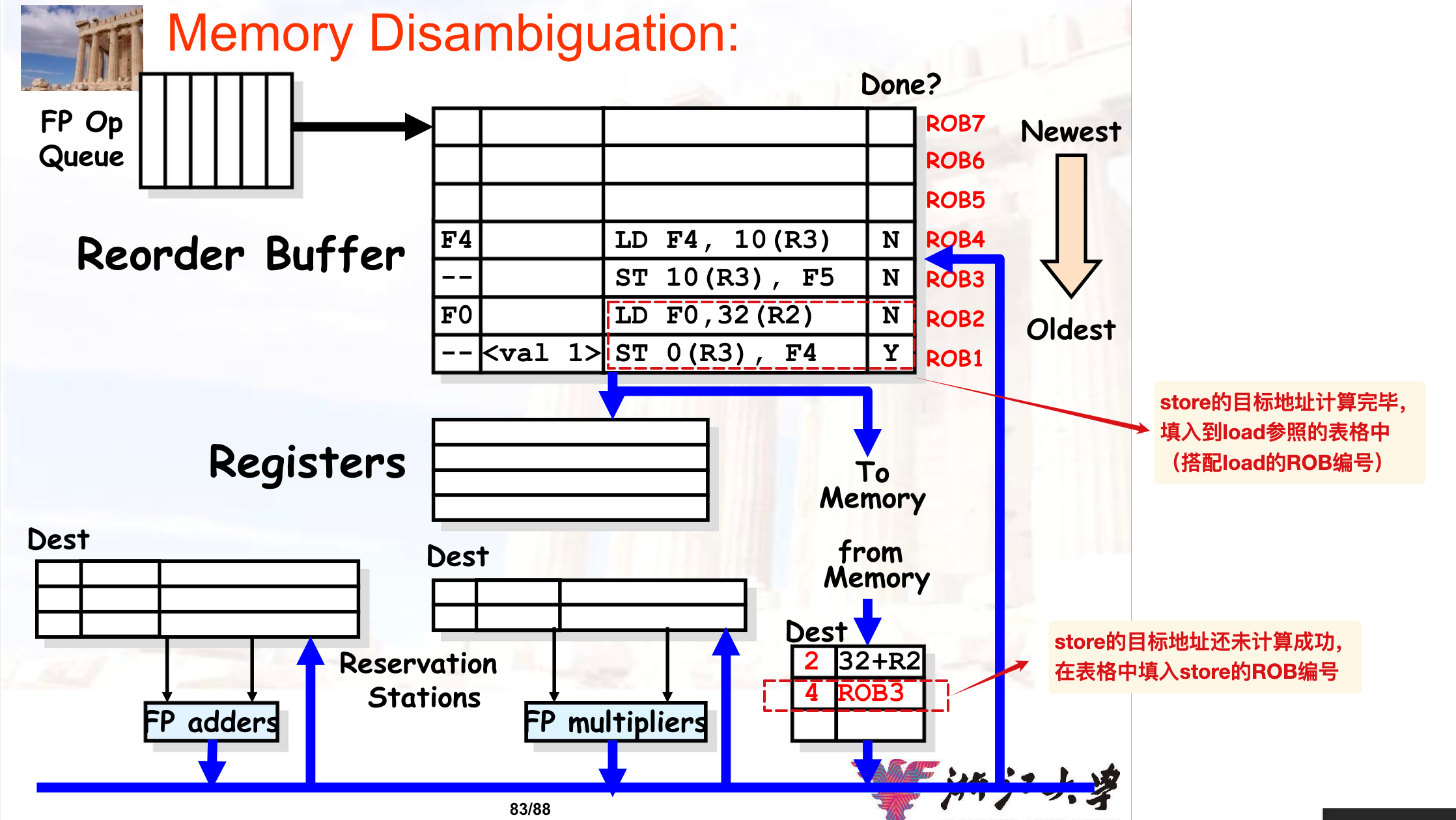
此处右下角的应该是load buffer?所以实际填写的不是存在冲突的store地址,而是load的地址;
猜测是这样的流程:如果load前面的某个store的目标地址还没有计算完毕,就将load的地址栏填入store的ROB编号,然后store完成的时候带着ROB编号在load内部检查,同时让store的地址与load的实际地址进行比较?
所以上图中的“填入到load参照的表格中”有问题
总结
Tomasulo也无法解决RAW冲突,这是无法解决的冲突
分支预测技术
分支预测表
- 一位预测器:分支历史表,使用PC的低位作为索引,0预测不跳转,1预测跳转
- 两位预测器
- N位预测器:
- 使用
来预测不跳转 - 使用
来预测跳转 - 如果要求计算准确率,注意是等到稳定的时候再计算(一开始的初始值并不重要)
- 使用
相关预测器
当前分支指令依赖别的分支指令的结果:
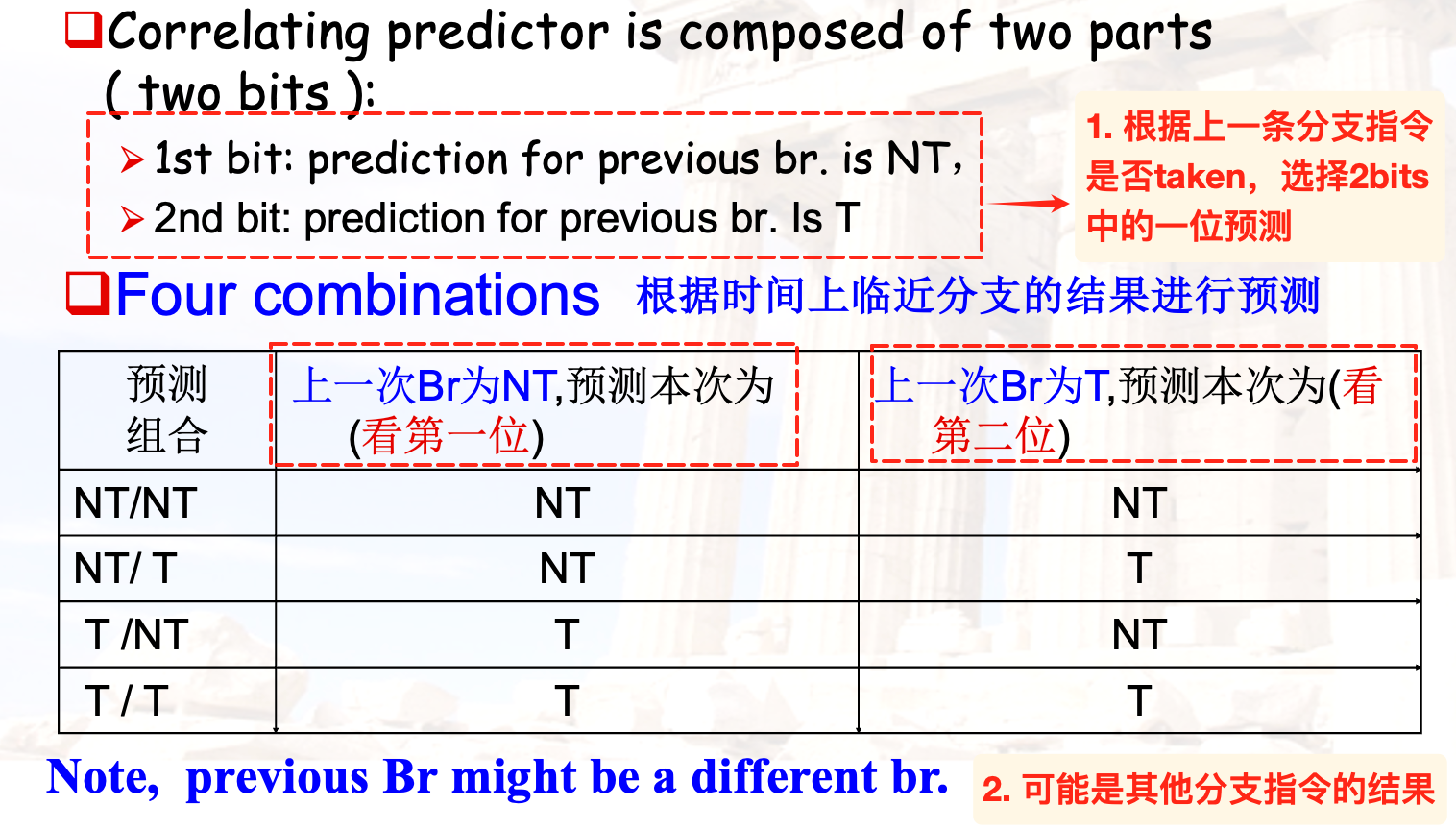
m,n预测器
- m:使用m位的移位寄存器来储存m条指令是否跳转的结果
- 每当得到一条最近的指令是否跳转的时候,就进行移位并填充0表示not-taken 或者 1表示taken
- n: 使用n-bit来预测当前指令是否跳转
- 分支预测缓冲区:一个记录分支跳转历史的buffer,使用上述的m-bit global history + 指令的低位进行index,每一行都对应了指定分支指令的预测器

预测器大小的计算
实际的硬件组成:
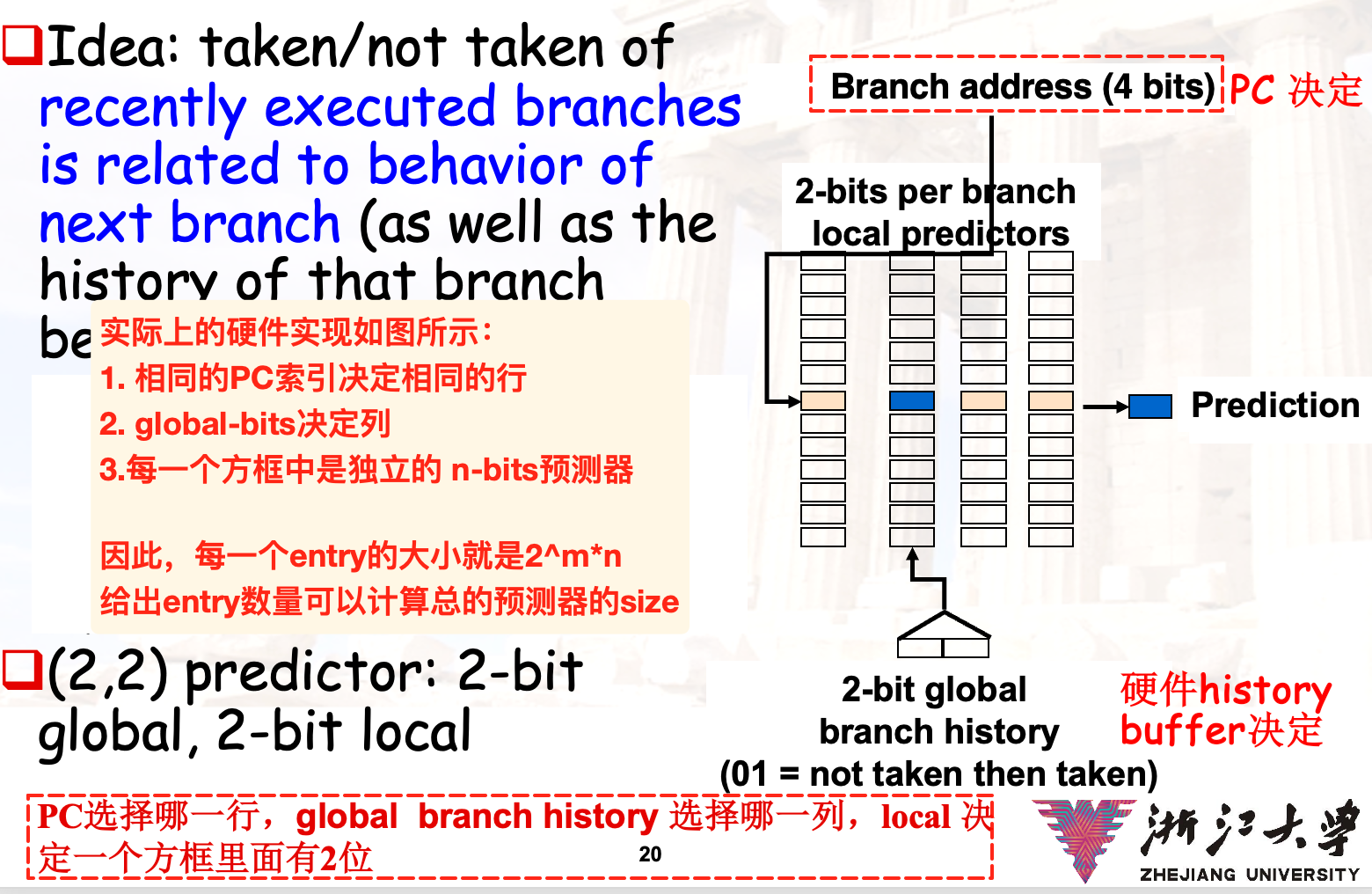
对应的大小计算:

其他预测器
- Tournament predictor:为了避免PC低位的相同干扰, 采用
global和local两个预测器,但是区别于上述的预测器,此处二者采取或得到对应的预测器- TODO:课件3.2的size计算
- Gshare预测器:将PC低位和历史记录进行异或, 从而进行选择
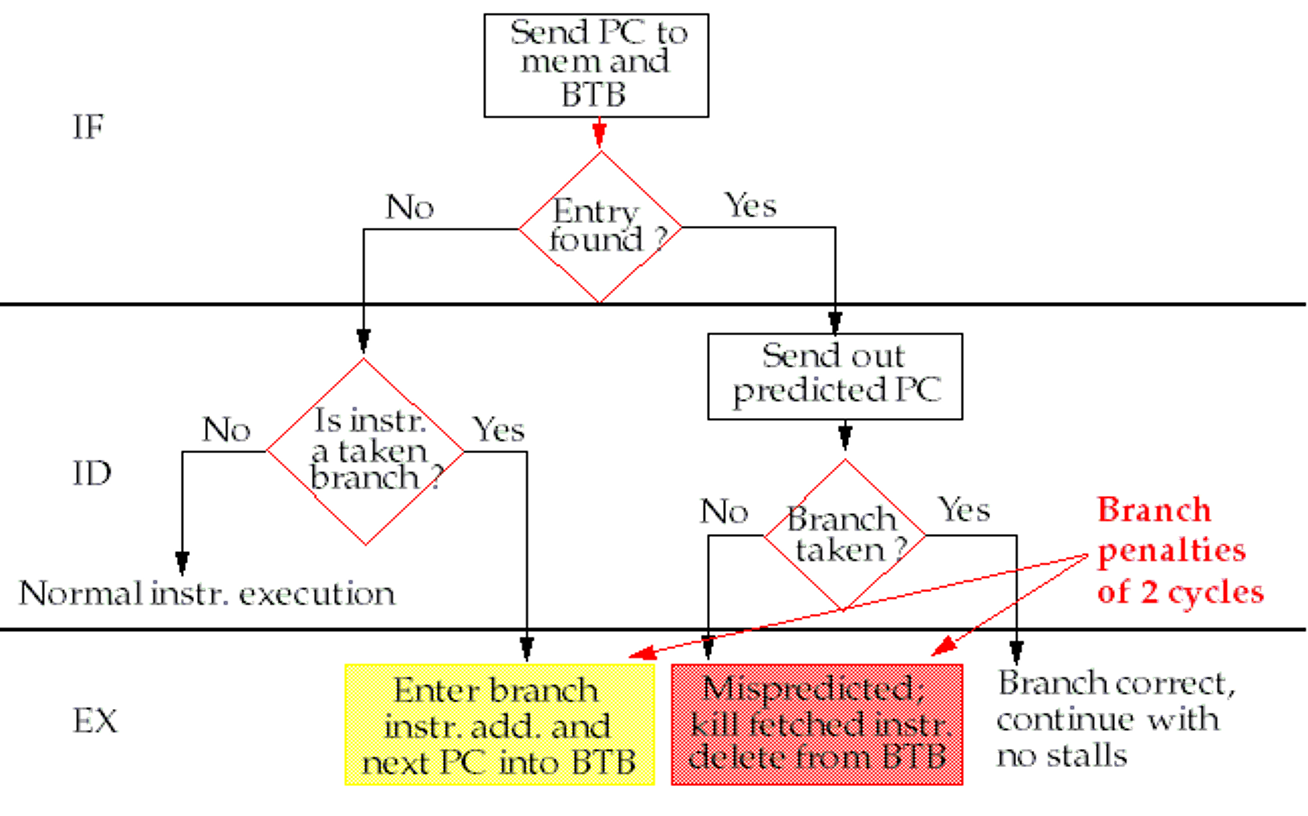
BTB
branch target buffer | 分支目标缓冲区
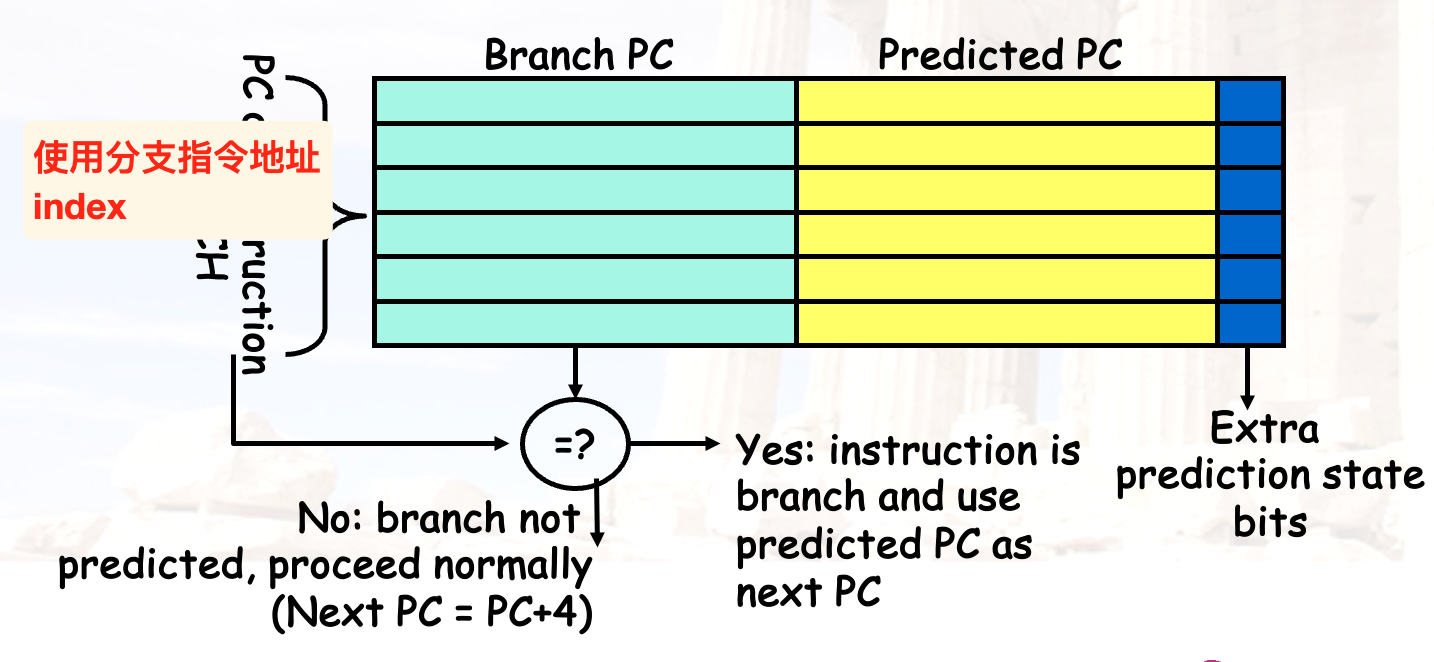
- 记录分支指令预测的跳转地址
- 利用指令地址index,如果在BTB中找到了就取出预测地址并执行
- if branch taken,照常执行,没有stall
- if not taken,将fetch的ins.清空,并且将预测错误的entry从BTB中删除
- 同理,如果一开始没有在BTB中index找到对应指令的entry,并且结果显示指令需要跳转,就在BTB中加入这一对的entry用于之后的快速预测
Integrated Instruction Fetch Units
随着CPI降低,取址单元可能成为瓶颈
因此,考虑将fetch unit与分支预测器、指令预取器以及指令的buffer相集成
Return Address Predictors
预测目标地址在运行时变化的间接跳转的技术。
将返回地址记录在类似于栈的buffer中,避免到内存中取返回地址,加速函数的返回
分支预测技术总结

CH4 DLP
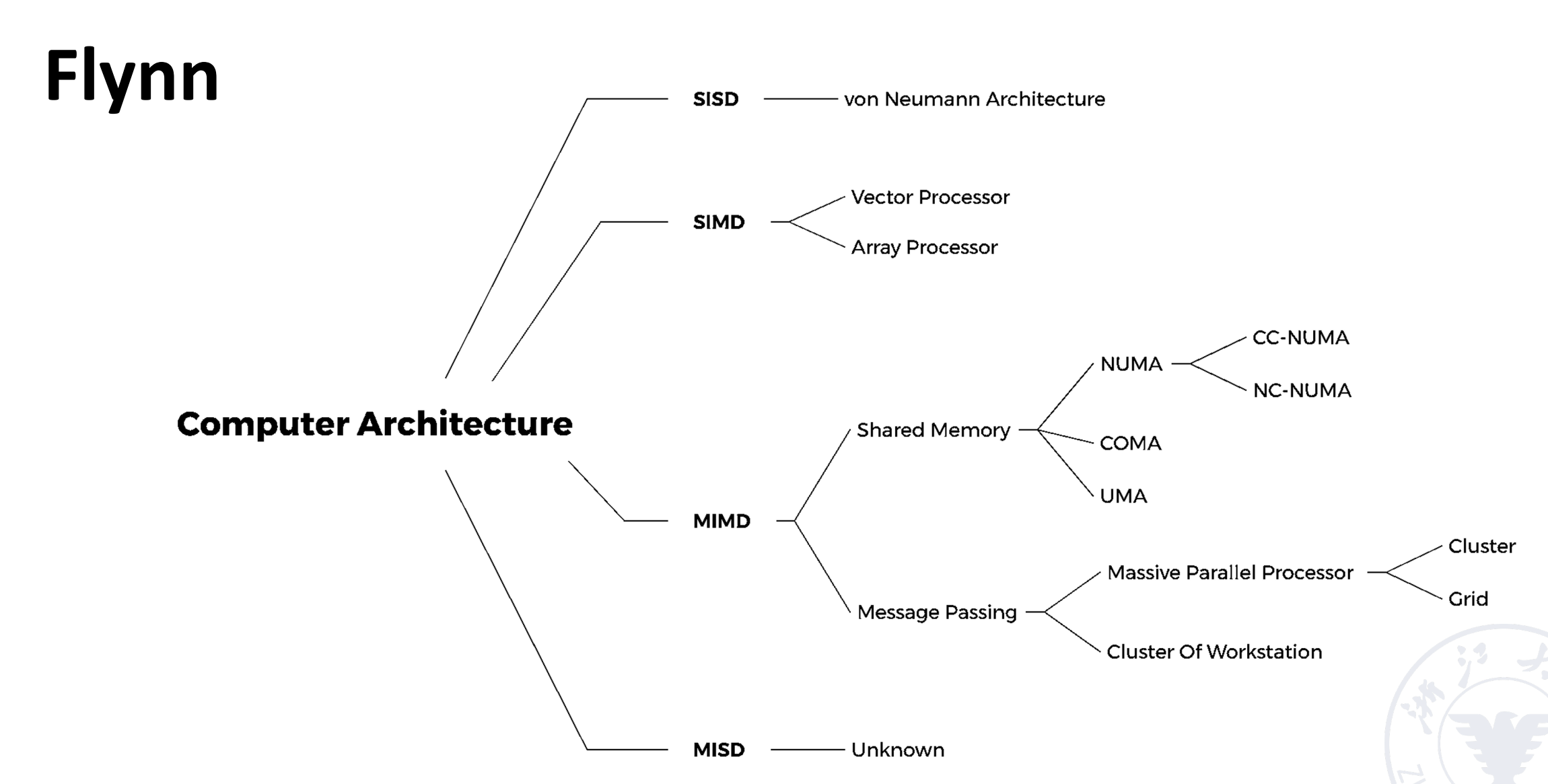
Flynn标准分类
- LLP时的依赖检查:关注是否在同一层读取了其他层写入的结果
- 可以使用本层中串行计算的结果
- reductions
Rename来解除依赖

根据题目找到对应的依赖,然后据此rename寄存器
Strip Mining 条带挖掘
MVL指的是向量处理器中寄存器最多的字长.
当用户实际的处理长度超过MVL时, 进行取模, 首先用标量处理余数, 然后用向量计算剩余的部分.
一个简单的例子:

向量机的问题
- 需要 set-up 时间;
- 内存的访问带宽会影响向量机的性能
提升向量机的表现
convoy:
- 可以并行的向量计算指令的集合
- 不存在结构冲突
- 可以通过vector chain来解决RAW冲突
chime :the unit of time taken to execute one convey
Vector Chaining
解决了RAW的冲突.

实际等价于流水线的 forwarding. 不同的是向量机是对向量的打包计算.
Conditional Execution
为了处理 if 语句的优化.
1 | for(I=0; I<N; I++) |

V0就是其中的标志寄存器.
根据标志位, 选择需要的位进行计算(压缩), 然后将其扩展成完整的向量.

sparce matrices
为了解决矩阵乘法中太多0的问题.
涉及到 Vector Scatter/Gather 的方法, 实际就是不连续的访存操作.
gather:从不连续的地址读取并加载到一个向量寄存器中
1 | for (i=0; i<N; i++) |
对应的指令: (
LVI)
1 | LV VD, RD ; Load indices in D vector |
scatter:将一个向量寄存器中的数据写入到不连续的地址中
1 | for (i=0; i<N; i++) |
对应的指令:(
SVI)
1 | LV VB, RB ; Load indices in B vector |
Multi-lane Implementation
同一个向量指令的不同分量,可以在不同的lane上执行
不同的lane之间不能存在数据冲突
在多个FU的流水线中优化:

Chain & Multiple Lane
可以将上述的思路和chain相结合.
向量机通过展开, 减少了条件判断等指令来减少了指令数.
- 操作数指的是涉及的运算个数(比如一条向量计算涉及512个操作数, 但是指令数是1).
编译器和用户可以互相提示数组是否可以向量化.
SIMD: single instruction multiple data
GPU
Graphical Processing Units.
采取 SIMT: Single Instruction Multiple Thread.
- 每个线程负责一条指令的部分计算.
thread => block => grid
与向量机的主要区别
- 不存在标量处理器
- 使用多线程解决内存访问的延迟
- 向量机通过bank扩大内存访问的带宽
- 具有很多的function units (类似于具有很多小的处理器.)
术语
warp
- 32 threads ==> warp / SIMD thread
- 必须执行相同的指令.
- warp之间不存在数据依赖.
PTX
对应的机器汇编.
predicate register
谓词寄存器, 类似于向量机中的标量寄存器.
MEM层次
- private memory
- local memory: 1个block内部共享
- GPU memory: 公共.
循环级别的并行
有的循环间的数据依赖可以被消除:
1 | for (i=0; i<100; i=i+1) { |
取出首尾的两条指令,改写:
1 | A[0] = A[0] + B[0]; |
寻找循环依赖

不同的迭代中, 存在读取和存储的地址相同的情况 ==> 存在循环依赖.
- 计算方式: If a dependency exists, GCD(c,a) must evenly divide (d-b)
- 通过枚举
来判断是否存在冲突,本质上就是图示的公式是否成立
可以通过变量的重命名来解决WAW等冲突.

CH5 TLP
其他概念
- NUMA又叫distributed shared-memory multiprocessor (DSM / DSP)
- UMA又被叫做 symmetric multiprocessors (SMP) or centralized shared-memory multiprocessors
概念区分
- coherence:规定了针对同一内存地址读写操作的行为
- consistency:定义了涉及不同内存地址访问时的读写顺序行为
硬件原语
exch用于将寄存器的值与内存地址中的值交换- 该操作是原子性的,一次性完成读取旧值和写入新值的操作
lr与sc
补充这部分的指令介绍,方便后续相关汇编的理解
Load-Reserved(加载保留)
- 加载之后在硬件层面预留了这个内存地址,表示有向其写入的意图,用于后续的sc指令是否允许写入
lr与ll也就是 load linked 本质上是一样的,只不过后者是MIPS架构中的指令名称,都是加载并预留的原子指令
Store-Conditional(条件存储)
- 尝试将值写入到内存地址;
- 只有在之前对该地址有成功的lr预留 且 未被其他处理器干扰的情况下,才能成功写入
- 具有返回值:
- 如果失败:返回0
- 如果成功返回非0

lr与sc的原子性操作应用

Note:Only Regitser-Register instruction can be insert between LL & SC
自旋锁
spin lock指的是程序陷入了不断尝试获得lock的loop
一个简单的版本
1 | li R2, #1 |
- R1所对应的内存地址保存了锁是否为空闲的信息,0 表示 free, 1表示被占用
- 上述版本将1加载到R2,并不断尝试将它的值与R1对应的内存地址的值交换
- 如果锁正在被占用,R2还是1,因此会不断陷入lockit的循环,直到某次的loop成功加锁(R2被交换为0),然后继续执行
上述的问题是,不断尝试 exch涉及到了多次的读写操作,会带来总线上的invalidate信号的traffic
因此,我们考虑采取下面的优化方案
优化的版本
1 | lockit: ld x2,0(x1) ; load of lock |
相比于简单版本的反复exch,优化之后的loop里只涉及到了读操作,因此对程序的表现更加友好
使用 exch的指令由于读写合一,操作不灵活,我们考虑将读写利用同样是原子性指令的 ll和 sc来分离,实现等价的效果:
采取LL和SC实现:
1 | lockit: lr x2,0(x1) ; load reserved |
因为lr、sc和exch一样,也是原子性操作,确保了“检查锁是否可以用”和“设置锁”不会被其他线程打断;
不同的是,exch通过交换之后的寄存器值来判断是否加锁成功,而sc利用自身操作的返回值来判断是否成功加锁
自旋锁的性能分析

TODO
Snoopy
两种转换规则:
一定要转换成 S 状态再read(除了自己read自己的hit);
一定要转换成 E / M 状态再write
P1写入X的新值之后,需要确保其他处理器知道变化,分为两种策略:
- Write Invalidate:将其他P的副本置为无效(搭配写穿透)
- 但是也适合写回策略搭配,注意dirty位的使用
- Write Broadcast:将其他的副本直接写入新值(搭配写回策略)
- Write Invalidate:将其他P的副本置为无效(搭配写穿透)
一个简单的例子;
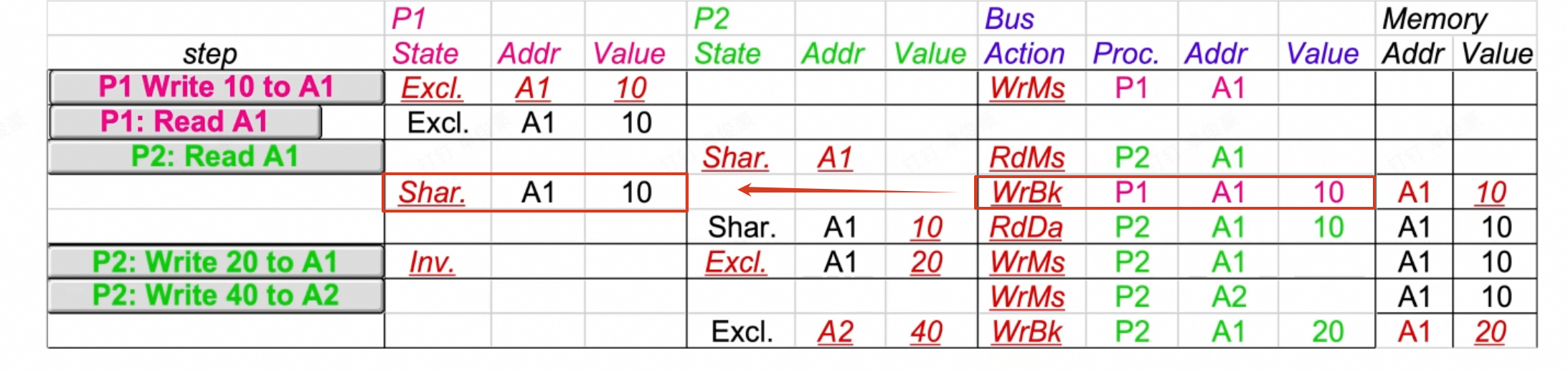
- 注意此时bus信号的桥梁作用:
- 发生了read miss之后,首先将P2的对应cache line设置为share状态(此时还不知道值)
- 总线信号传到P1之后,P1的对应状态修改为share,并且发起了write back的信号,将A1的值写入mem
- 之后,总线信号read data让P2读取了mem中的值,完成了
P2:read A1的操作
每一个处理器/线程对每一个block具有自己的状态
状态机
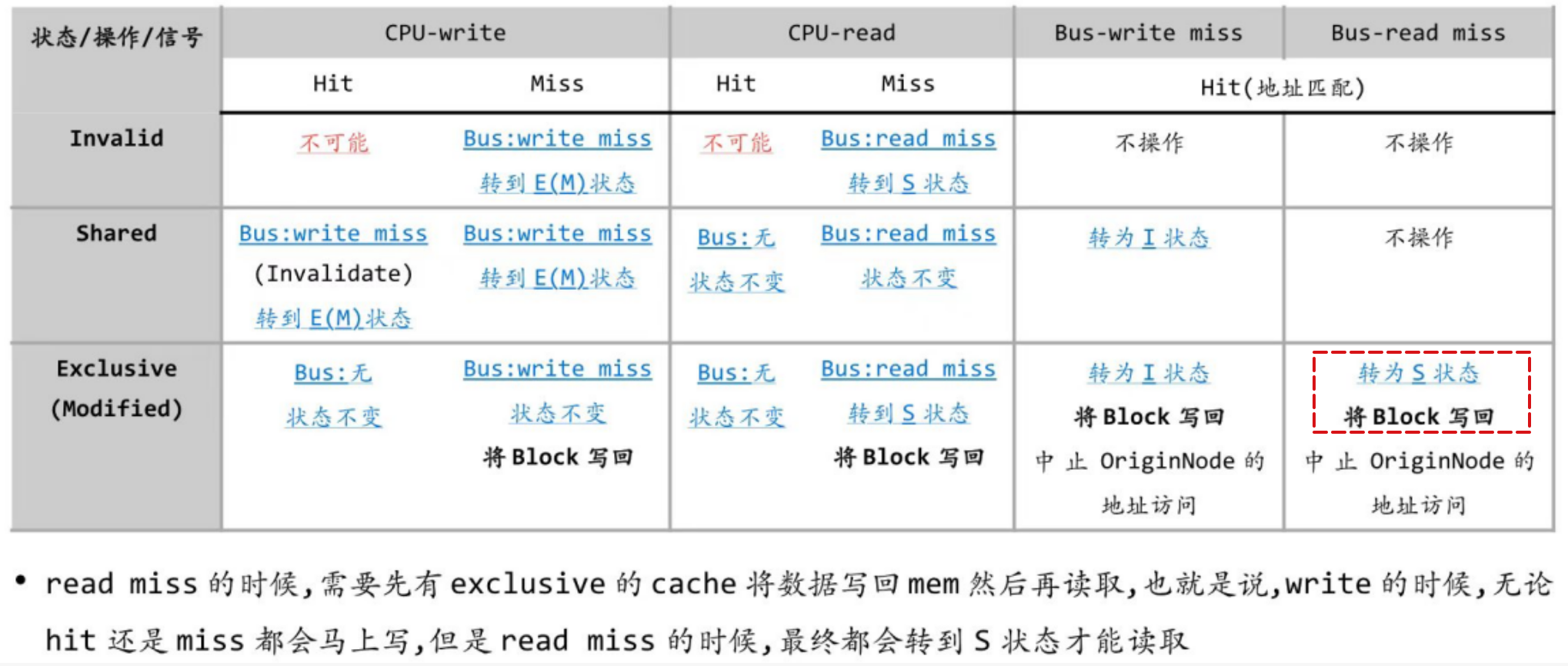
处于E状态时,如果收到了bus上的read-miss信号,会将该P改为S状态
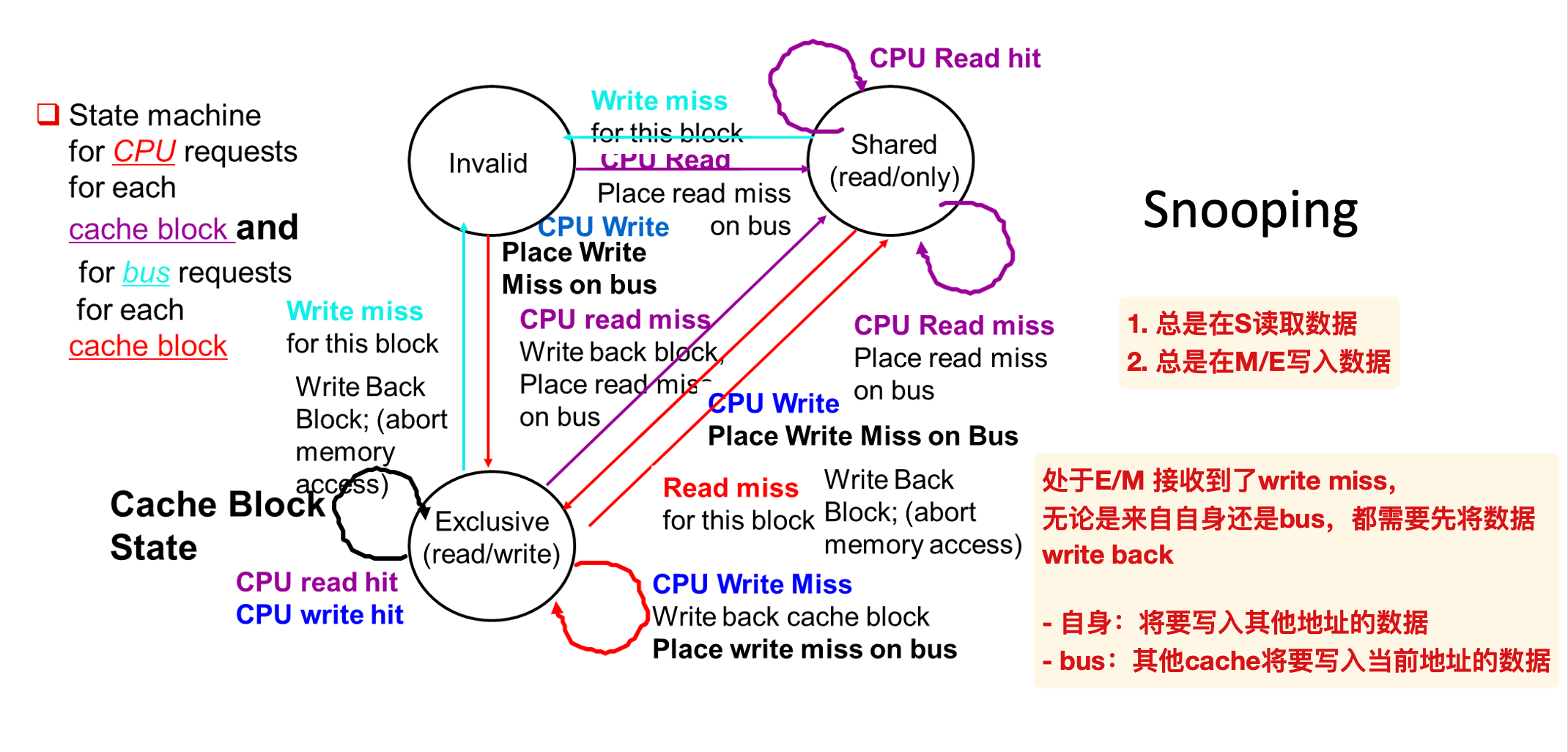
Directory
- local node 发起请求的处理器
- home node 对应地址所在的处理器
- remote node 拥有这个副本的处理器
在homeNode中存储一个block在不同处理器/线程中的状态
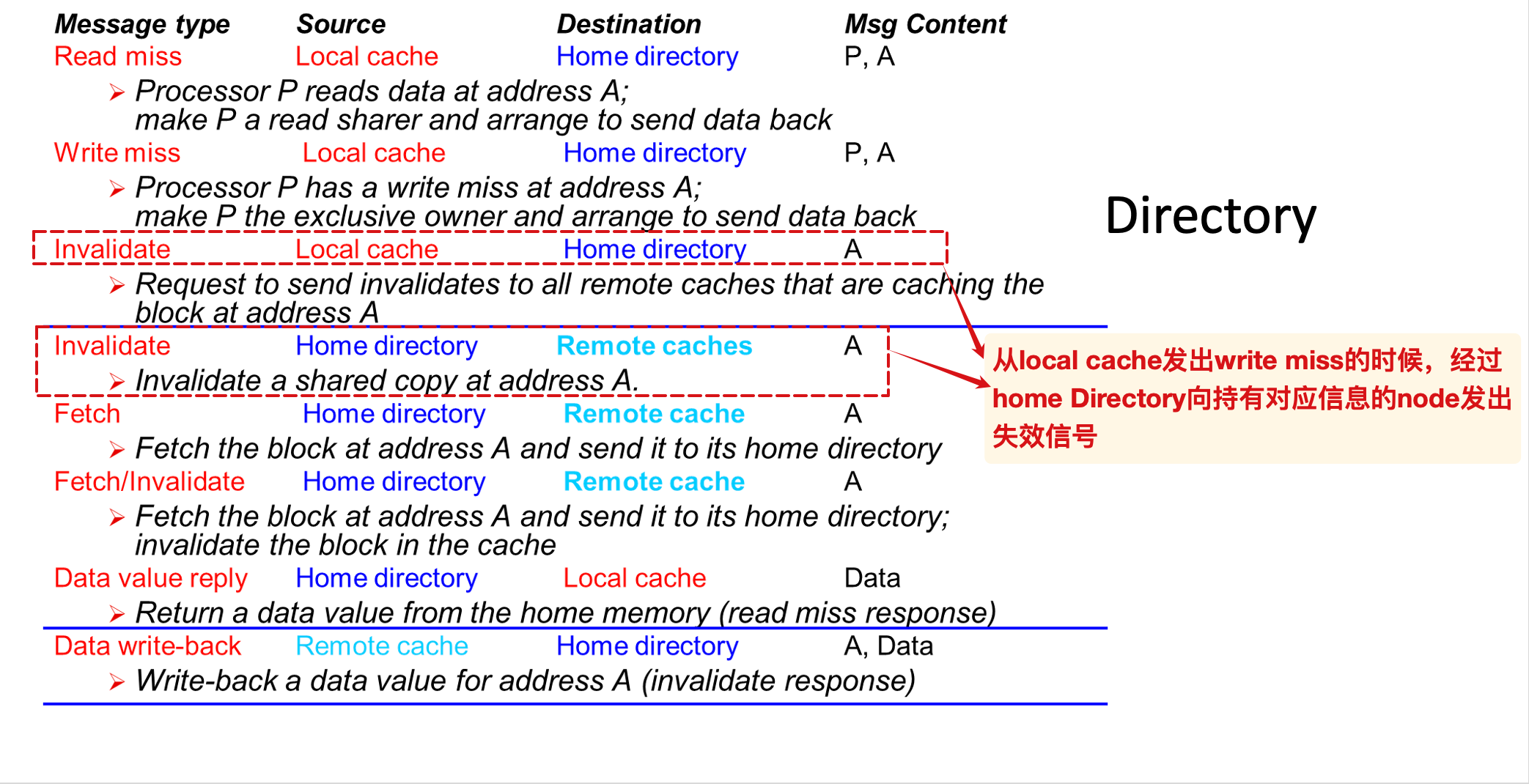
其中的
fetch/invalidate发生在:local发生了write miss,并且home中对应的block为E状态,向独占该block的P发送~信号,确保将仅在对应P中的数据读取再非法化(内存中数据过时)
- 读取之后的数据先存放在了home中,然后再由home发送data reply给local(一般来说local写入了新值,并不需要这个旧值;但是如果写入的新值是 X+1,就必须获得正确的旧值了,因此还是有必要的)
write miss
初始:
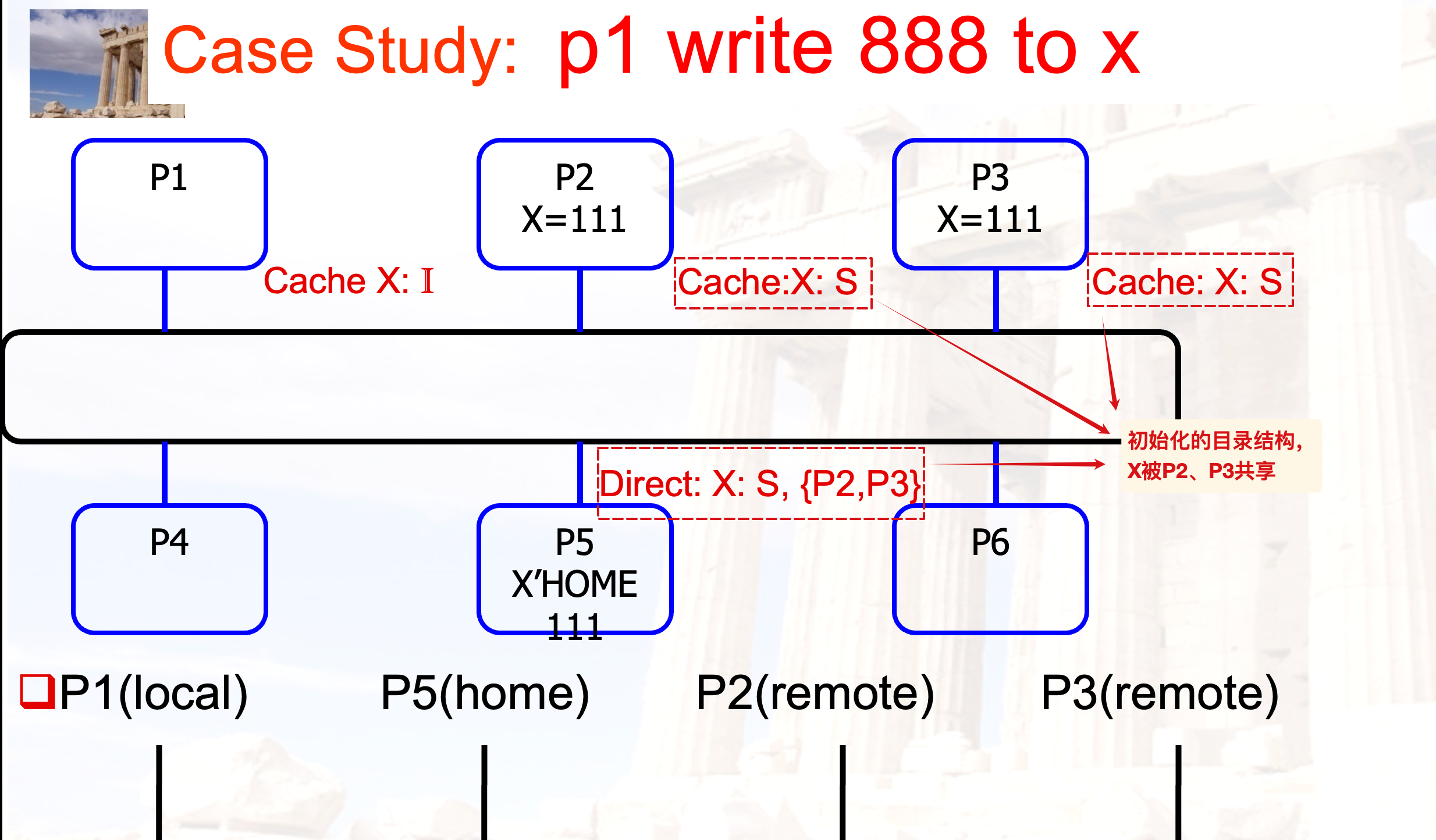
写入:
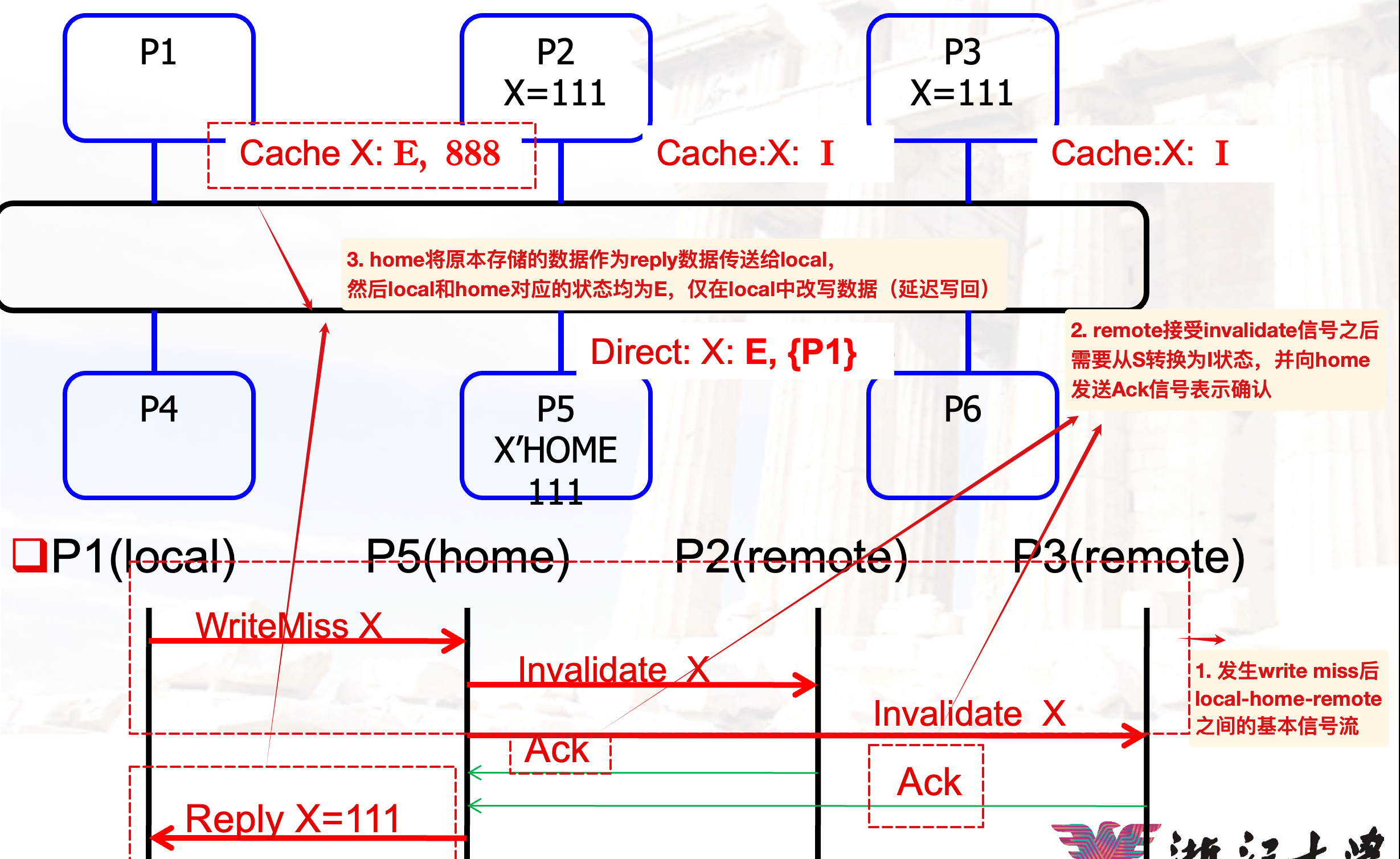
fetch/invalidate
初始:
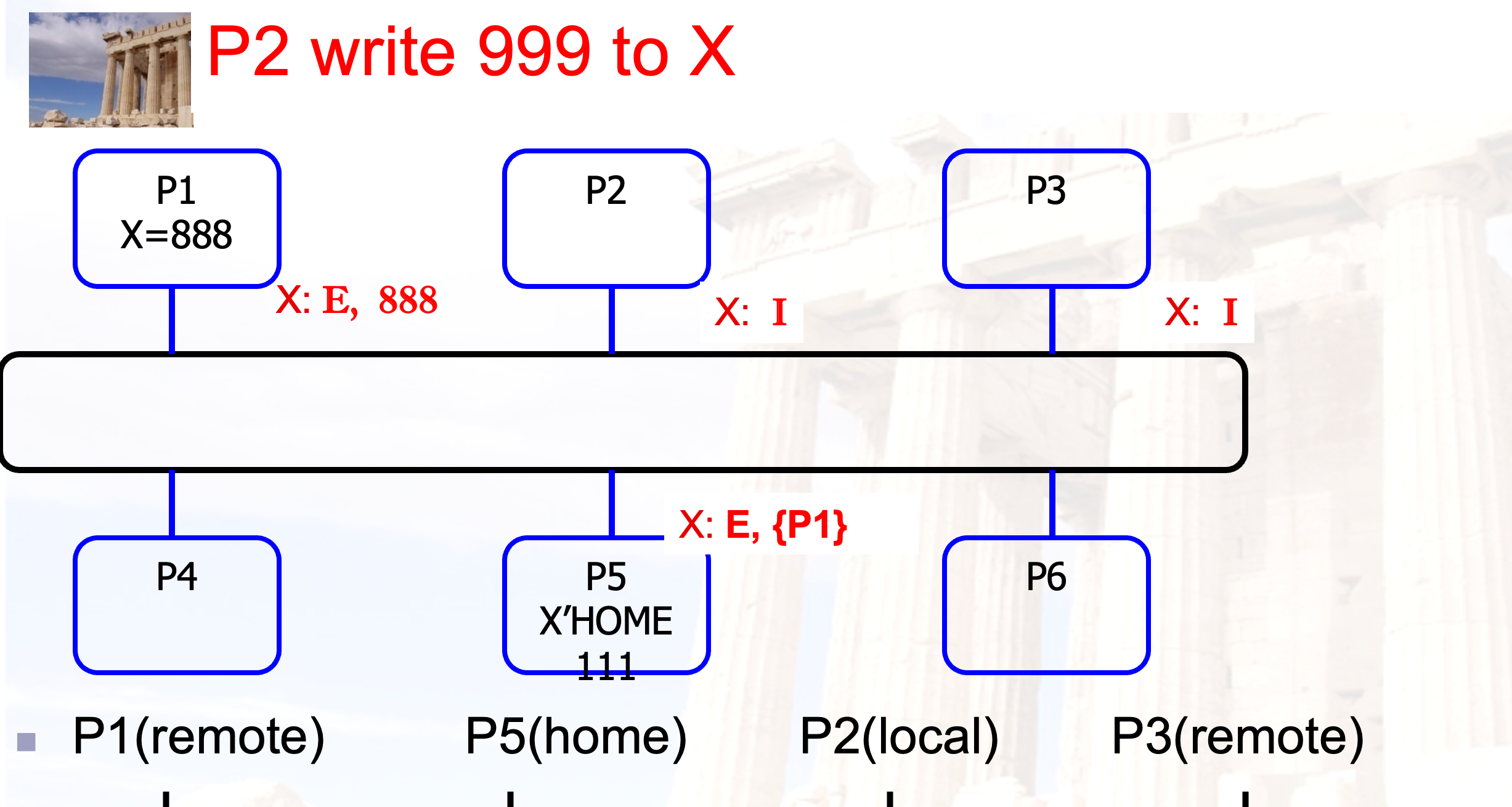
过程:
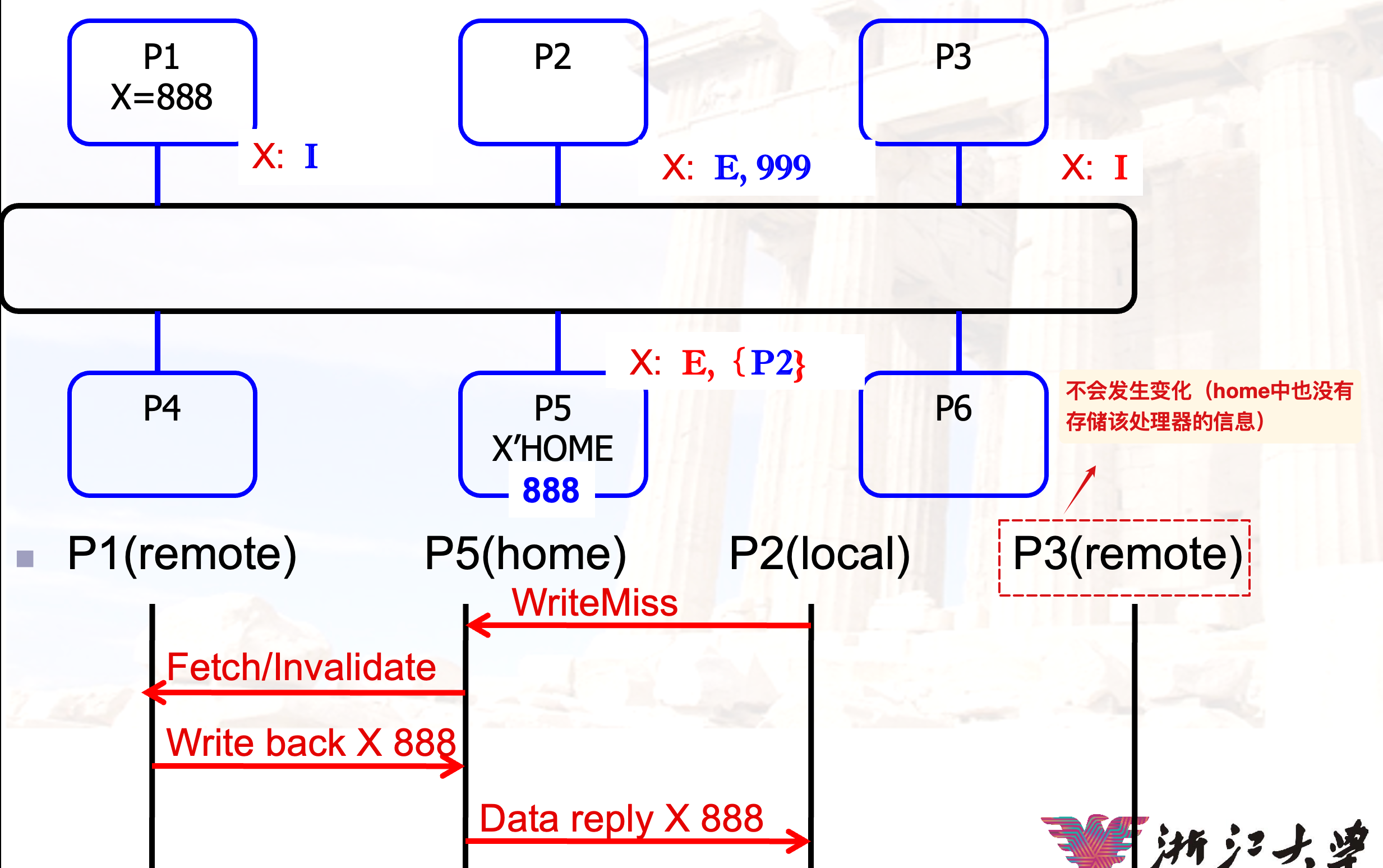
如果目录节点中记录的状态是E,就向对应的处理器发送
fetch的信号
根据cache填写目录
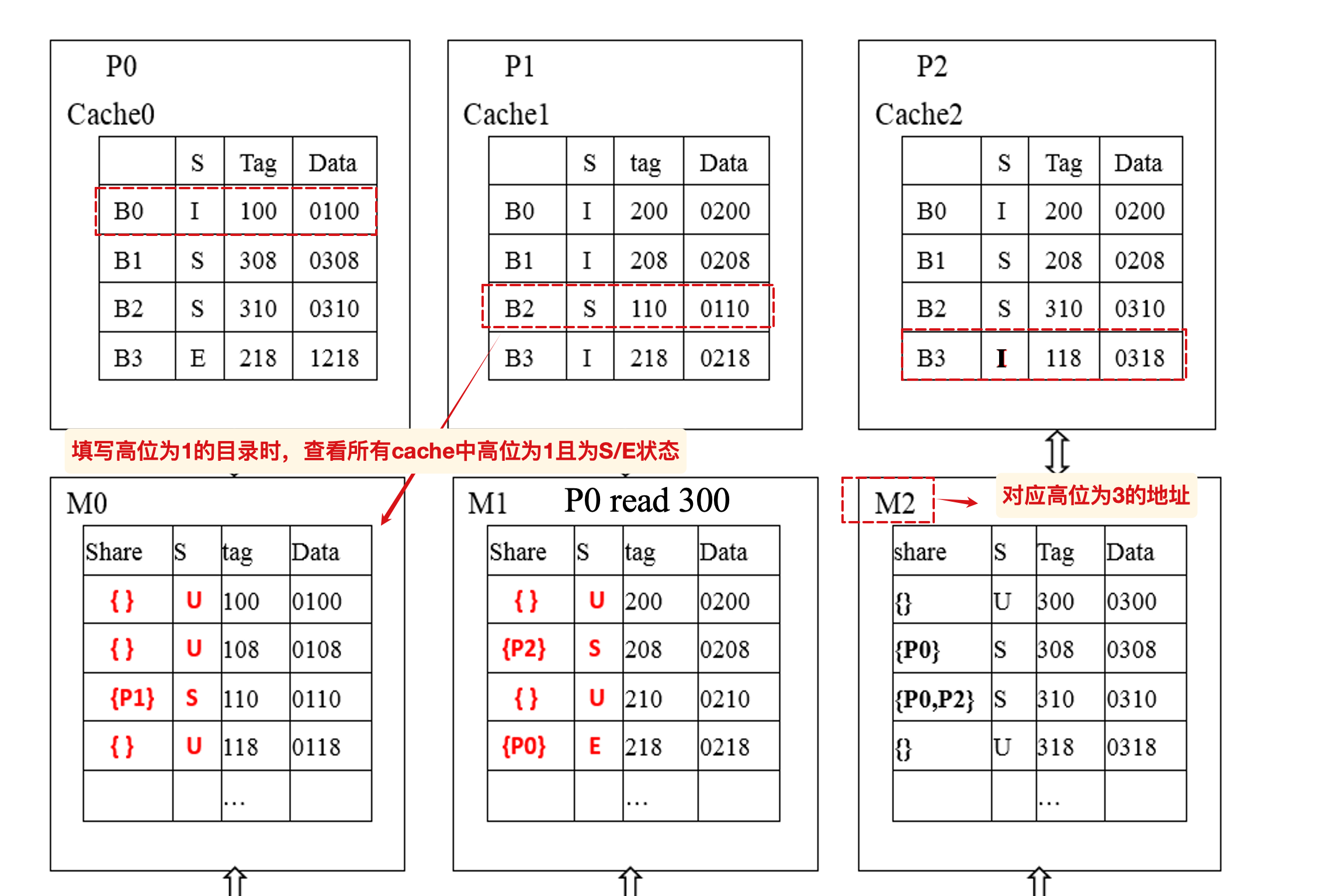
对应的简单例子:
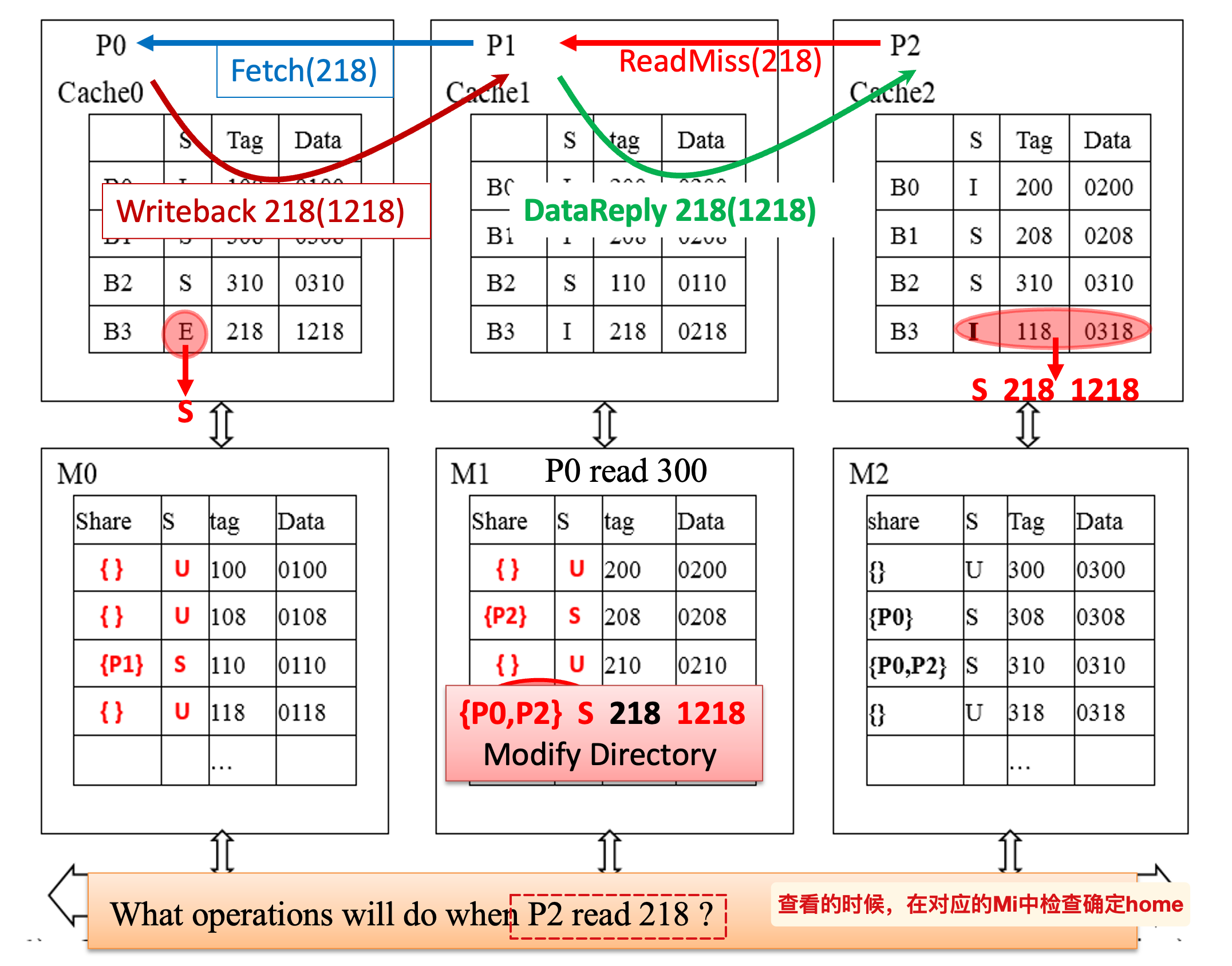
另一个语言描述的例子(答案):

22-23回忆卷的最后一题
cache失效问题
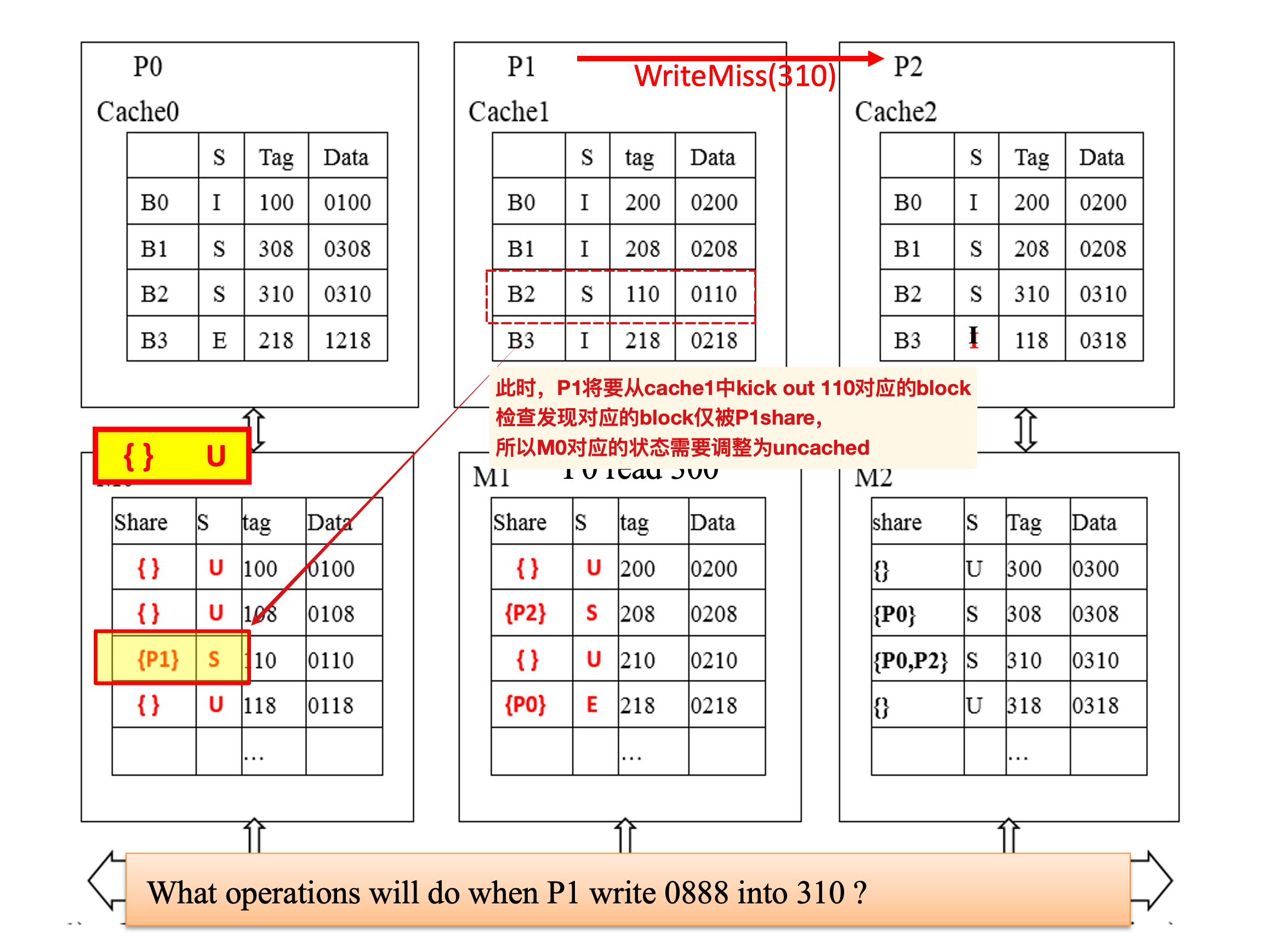
P将自己cache中的block kick out时,需要将对应的home中的sharer中将P踢出序列,如果原本仅有P本身,就需要将对应的状态改为U,表示uncached.
MESI
如果没有特别说明,就当做MSI
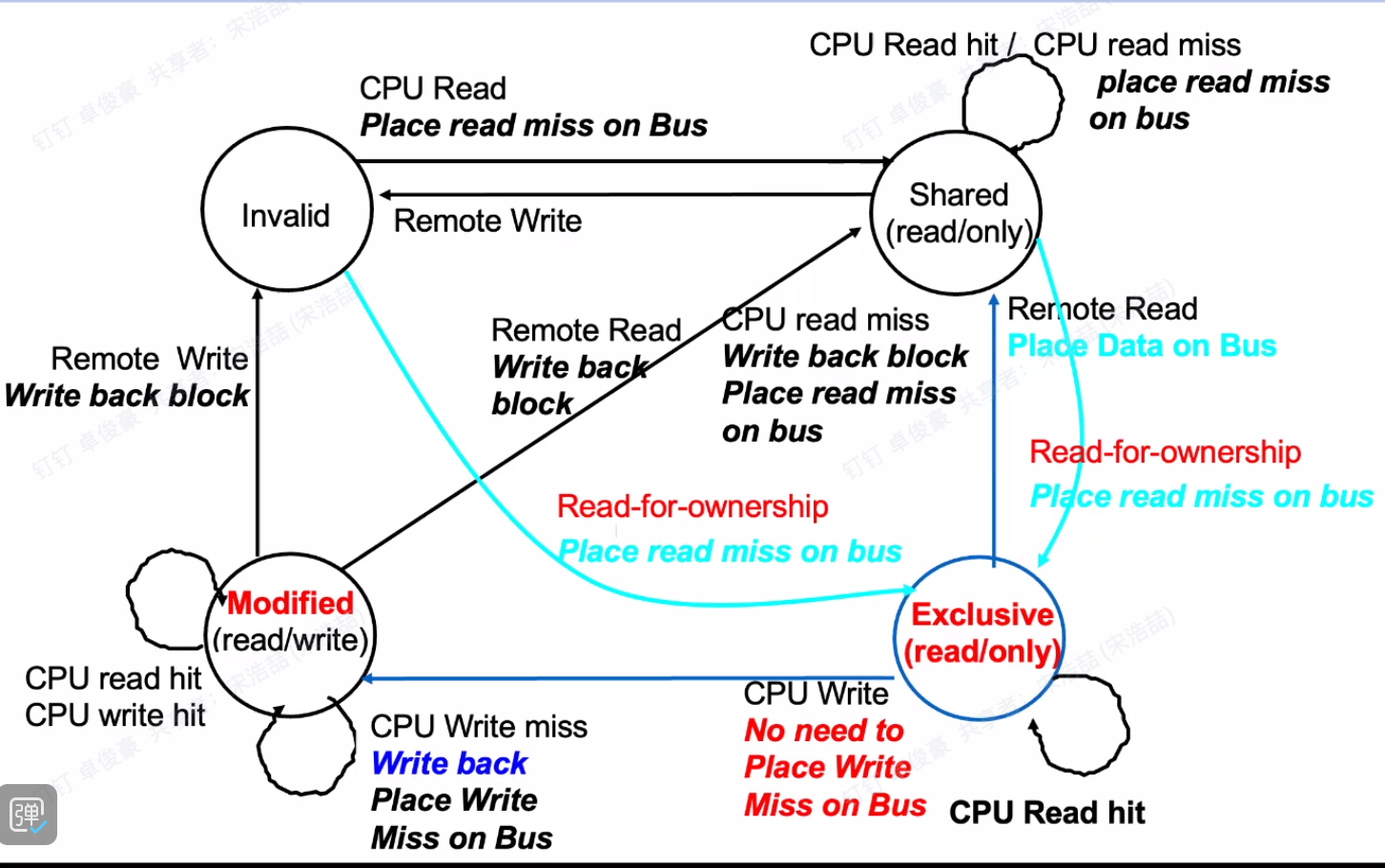
状态:
- Invalid: 缓存块无效,不能被使用;
- Shared: 缓存块未被修改,且可能存在于多个缓存中,内存中的数据是最新的;
- Modified: 缓存行已被修改,且该缓存行是唯一的有效副本,内存中的数据已过时;
- Exclusive:缓存块未被修改,且是唯一的有效副本,内存中的数据是最新的。
E的存在是为了优化写入性能和减少总线流量,具体来说,我们用E来区分某个缓存块只被一个处理器读取且还没有写入的状态,是为了在此后该处理器写入该缓存时,不需要在总线上发送Invalidate的信号(因为没有共享缓存的其他处理器)
如果是传统的MSI,即使share的成员只有一个,还是要发送信号到总线,被其他的处理器接收并处理,这带来了额外的时间开销
Consistency
Sequential consistency
特征:Delay next memory access until the previous one is completed.
对指令的执行有着严格的顺序要求,虽然保证了正确性,但是延时较高
- 相同处理器内部的内存访问是有序的
- 不同处理器的内存访问是交错的
课本的例子:
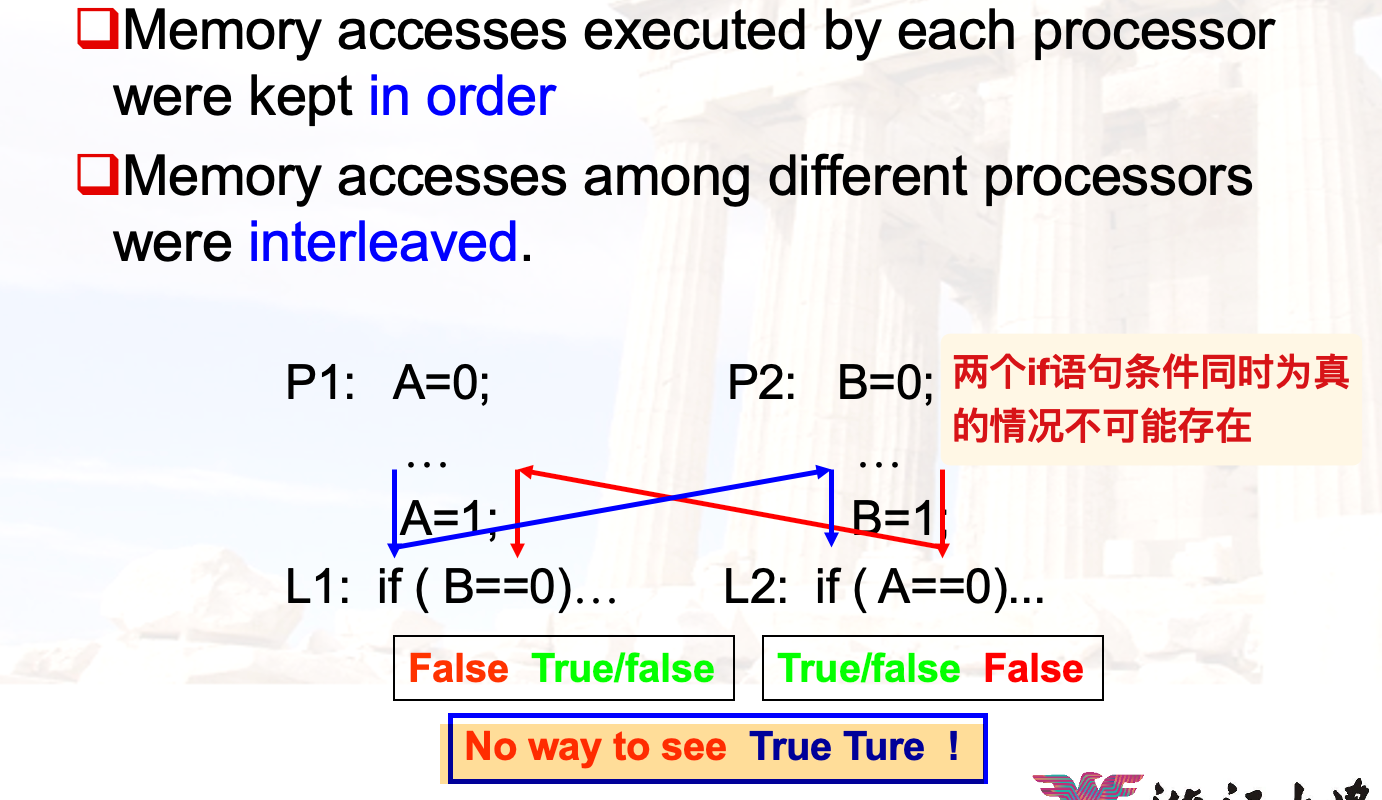
简单的计算:

Relaxed Models
为了降低SC带来的延时,我们采取 Synchronized program 来让指令的读写在乱序执行中保持与串行执行等价的效果,以下是不同等级的model:
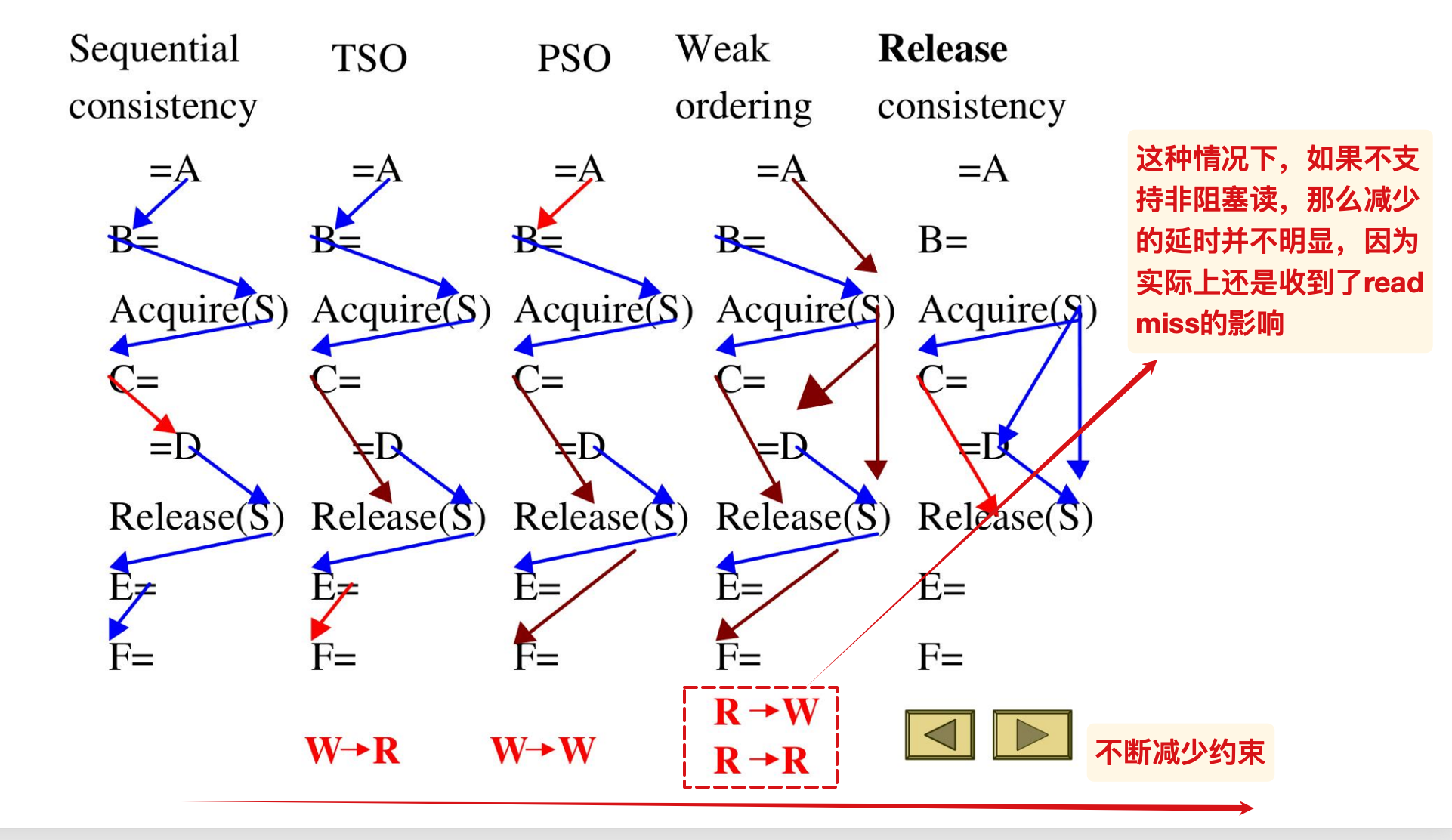
下方的顺序表示该模型在前者的基础上去除了对应的顺序约束,但是要求访问的对象不是相同地址的
比如在TSO中,
C=作为写操作,允许和= D的读操作一起执行,解除了W-R的约束
jxh老师的PPT
针对核心的补充摘录
Tomasulo的三个主要优点
- The distribution of the hazard detection logic
- 保留站和CDB
- 如果多条指令在等待一个结果 或者 一条指令等待多个操作数,可以同时通过CDB的广播读取(避免了通过寄存器读取)
- The elimination of stalls for WAW and WAR hazards
- overlap iterations of loops:循环迭代的重叠
- 相当于从HW(硬件)上实现了循环展开
计分板无法实现 overlap iterations of loops
为什么Tomasulo可以实现循环迭代的重叠?
- 寄存器重命名
- 保留站允许指令的提前发射以及旧值的存储(避免了WAR冲突)
- Tomasulo building data flow dependency graph on the fly.
计分板阶段的回顾
- ISSUE:当下面的条件同时满足时issue:
- 具有可用的功能单元
- 没有与正在执行的指令具有相同的目标寄存器
- 此时避免了结构冲突和WAW冲突
- RO:当两个操作数都准备好了的时候才会读取
- 避免了RAW的冲突
- EX
- WB:此时检测WAR冲突并在必要的时候stall
计分板和Tomasulo的对比

Tomasulo消除了WAW与WAR冲突;没有显式寄存器重命名的计分板无法消除~
OOO:out of order,此处指乱序完成
CDB的额外信息

TODO: 为什么需要source address?
使得CPI < 1的几种方法

向量处理;超标量;VLIW
超标量
使用基于Tomasulo的算法,可以实现乱序执行的动态调度
Issue Packet:
- 从fetch unit获得的指令组合,可以在一个周期内同时发射
- Issue阶段也被流水线化:
- 第一个阶段检查当前packet可以一次性发射的指令数(不存在数据冲突);
- 第二个阶段检查上一步选中的指令是否与已经发射的指令存在冲突
对于N-issue的多发射,每个cc实际发射 0-N条指令
多发射存在的问题
- 必须在一个cc内多次重命名相同的寄存器

- 拓宽总线
两种实现多发射的方法

- pipeline
- widen issue logic
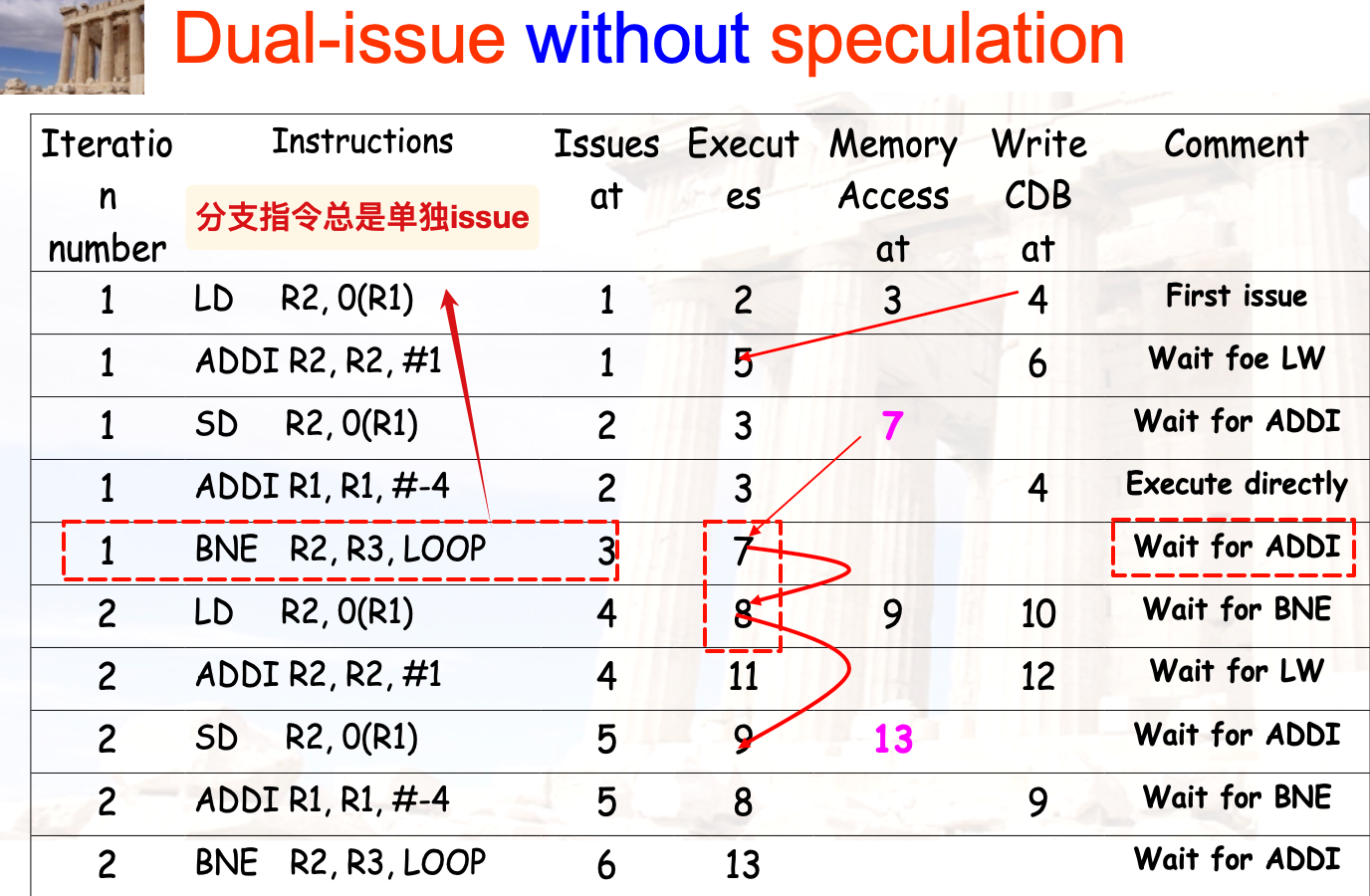
双发射的例子
不带投机执行的双发射:
带有投机执行的双发射:
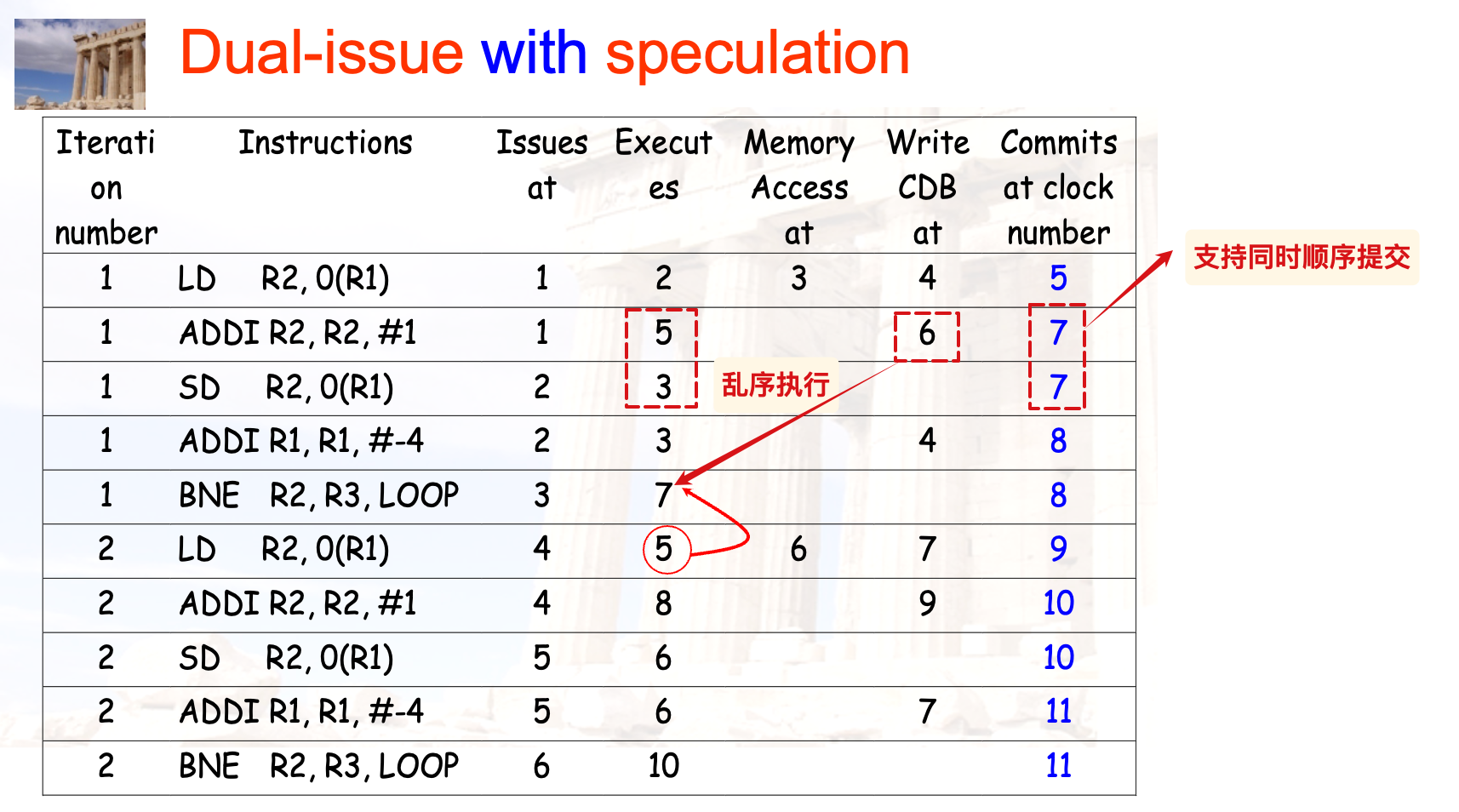
WB与IS的并行执行

然而事实证明很少会考虑这种情况?除非题目明确说明或者给出充分的暗示,否则认为还是在下一个cc才能issue到原本冲突的FU
Global code motion
全局代码调度:通过跨分支移动指令来有效地调度带有内部控制流的循环体。
DRAM与SRAM

大题整理
CH1
TODO
CH2
cache相关的计算题参考知识点梳理的ch2-cache performance
Global / Local Miss Rate

课本的例题:

分析:
- L1的global和local缺失率相等,都是 40 / 1000
- L2的global缺失率为 20 / 1000, local缺失率为 20 / 40
AMAT:
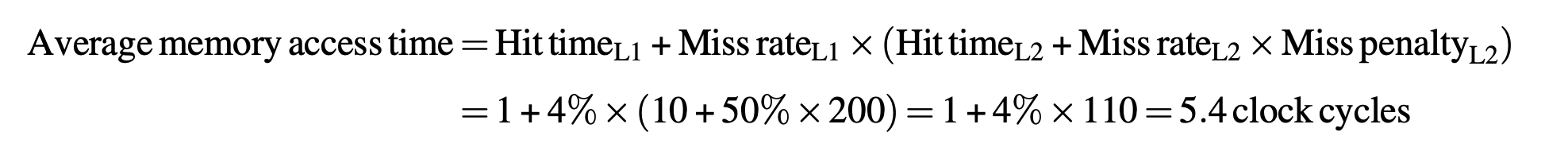
Average stall cycles per instruction:( AMAT - hit time ) x MPI = (5.4-1) x 1.5 = 6.6 cc
是否满足时间和空间局部性

分析:根据给出的cache容量、组关联等信息计算block的大小,然后比较block大小是不是大于系统的字长(如果小于就不满足空间局部性)
此处计算得到block大小为 8KB / 4K = 2B < 4B
似乎有cache就一定满足时间局部性?如果按照byte访问的话,能够存储指定的word就可以?
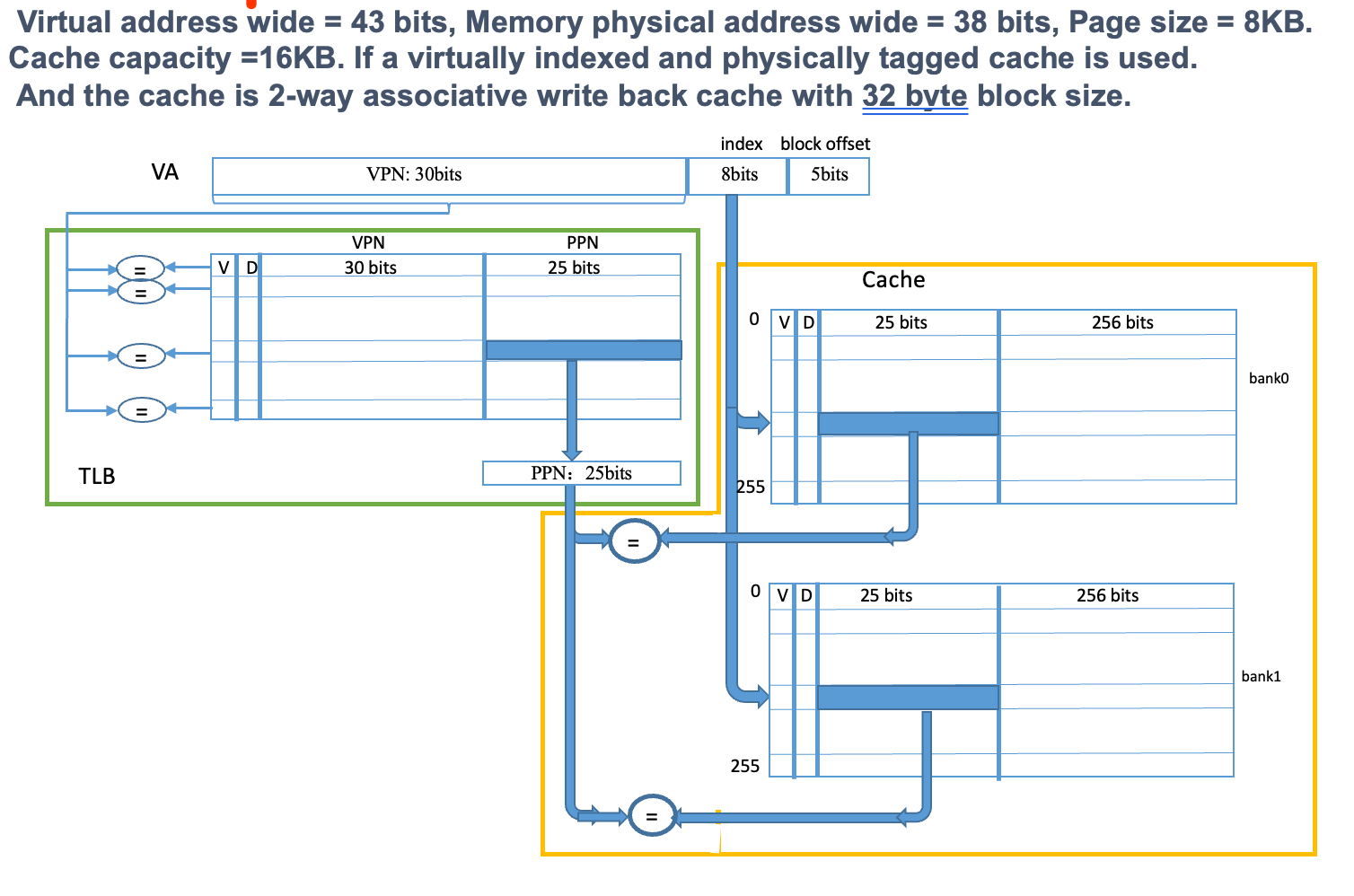
cache与tag
给定物理地址的宽度 ,cache的容量和组关联度
假设block是
- byte offset bit =
- index bit =
- 所以tag的位数是:地址位数N - n

虚拟页的容量和虚拟地址的位宽在此为干扰信息;
如果不是直接映射,就先计算一个set的容量,然后据此计算index
假设组关联度是
- index bit =
- 对应的tag位数 = N - n + i
由此可见,题目中没有给出的block的容量恰好是不需要的计算量
e.g. 加入组关联:一个8-way的例子

CH3
建议参考老师的ppt推一遍计分板和Tomasulo的填表,然后记住什么时候要推迟一个cc、什么时候可以直接执行
延迟一个cc的情况
- 计分板和Tomasulo存在结构冲突时,上一条指令WB之后的一个cc下一条指令Issue
- 计分板和Tomasulo的指令需要读取待写回的数据时,上一条指令WB之后的下一个周期分别进入RO / EX 阶段
但是Tomasulo的issue队列里可以直接在上一条结束的cc接替执行下一条的EX:
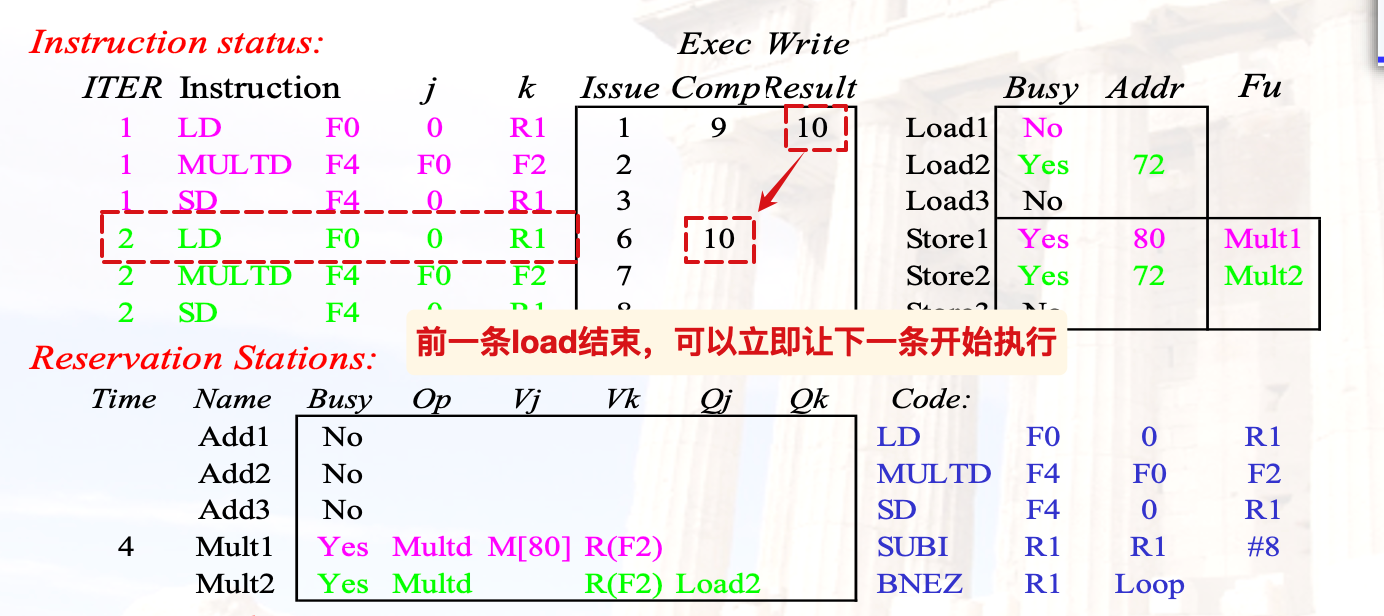
CH4
rename 、 string strip和循环级别并行部分的例题请参考知识点梳理部分
convoy与chain
详细内容可以参考英文第六版的p291

参考解答:

此处忽略了向量机的set-up等时间
下面是回忆卷:

参考答案:个人观点
第一问:
- 指令的执行时间分为:取指+启动+向量长度, e.g. 第一条vld为 1+4+64 = 69
- 但是后续的指令的取指可以在前一条指令执行期间完成,因此此处的vadd可以在cc=69开始执行:69 + 7+64 = 140cc
- 后续指令同理分析
- ….
第二问:3(vsd与vld存在结构冲突)
第三问:
- 估计:3x64 + 3 + 7 + 10 + 4
- 考虑了取指时间以及各个convoy内部最长的启动时间
blocked 与 unblocked
Here is a blocked and unblocked version of C code to perform a matrix operation on a 256x256 matrix:
1 | for (int i = 0; i < 1024; i += 16) { |
1 | for (int i = 0; i < 1024; i++) { |
Suppose the size of the element in the matrix is 32 bits and we execute the codes above on a processor with a 2KB fully associative data cache using the least recently used (LRU) replacement strategy. The cache block size is 64 bytes. What is the relative number of cache misses when running the blocked and unblocked version?
A. 2 : 17
B. 1 : 8
C. 1 : 17
D. 1 : 16
A
SOLUTION:

之所以说blocked version一轮循环只会发生32次miss,是因为计算得到这个cache正好有32个cache line,因此在内层循环所需的32个block都只需要读取一次;
因此,我们首先根据题目给出的cache容量和block信息,算出index;然后结合元素的大小计算内层循环需要的block数量,检查是否可以被cache存放
CH 5
TODO: 感觉记一下例题就差不多了(知识点梳理部分)
小贴士
- precise exceptions:
- 定义:On handling exceptions, if the pipeline can be stopped so that the instruction issued before the faulting instruction complete and those after it can be restarted
- 计分板的WAW冲突检测:Scoreboard Algorithm issue a instruction when no other active instruction has the same destination register to avoid WAW hazard.
- 写更新也就是写广播,与写失效构成了常用的处理缓存不一致性问题的策略
补充
常见的CSR
常见的CSR有mstatus,mtvec,mepc,mcause,mtval。这些寄存器都属于M mode:
- mstatus:机器模式下的状态寄存器,包含开关中断的MIE、保存进入异常之前特权模式的MPP等
- mtvec:发生异常时跳转的PC入口;
- mepc:发生异常时,指向导致异常的指令;发生中断时,指向中断处理后应该恢复的位置;
- mcause:根据异常来源设置
- 如果是访问存储器造成的异常,就将其地址更新到mtval;
- 如果是非法指令导致的异常,将指令编码更新到mtval寄存器中
- mtval:反映引起当前异常的存储器访问地址或者指令编码
VIPT
Virtual Indexed and Physically Tagged Cache
也就是从VA中提取低位作为实际物理地址对应的index,用VA的高位在TLB中查询得到物理地址,然后用物理地址中的tag进行比较。这两个步骤分别称为 缓存查找和地址翻译 ,可并行执行
这样做是为了消除同义词问题:
- 如果采取完全的虚拟地址寻址VIVT,一个物理地址可能对应不同的虚拟地址,从而导致其具有了多份的拷贝,带来了数据的不一致性的问题
写失效的冲突写

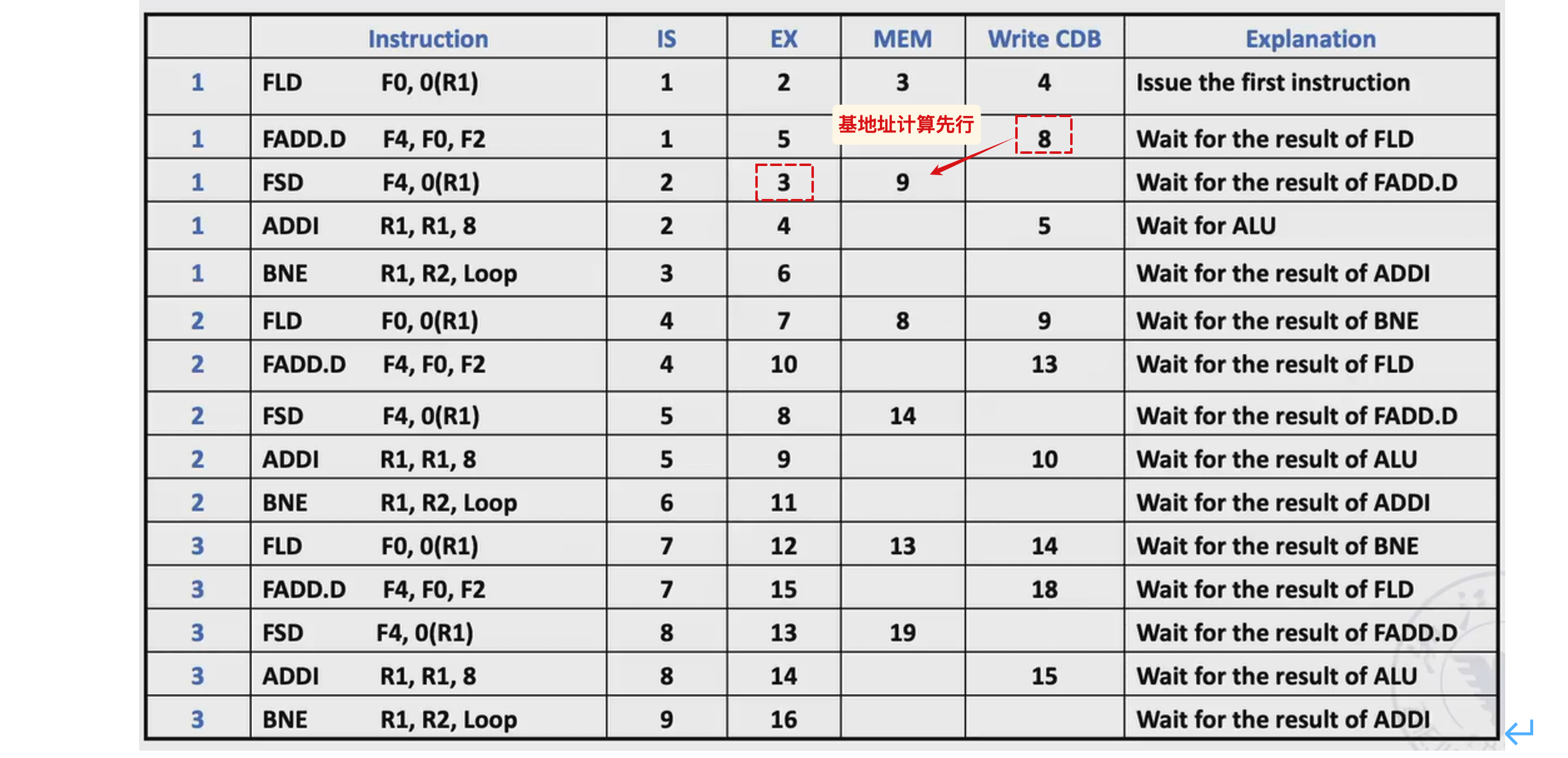
带有投机的store

由于带有投机的Tomasulo在commit之前都不会实际更新寄存器或者mem,所以 store指令在此之前不会实际向内存中写入数据,那么我们可以在其地址相关寄存器准备好的时候就进入Exe阶段(地址计算)
实际上,不带投机的store也是这样(参见下面“多发射的例子”中的标注)
相应的,当 store指令结束write result的时候如果此时还没有准备好源寄存器的值,就会在ROB中记录(对应指令的ROB编号),并在对应指令完成后准备好commit
由于每条指令都只在ROB有空位的时候issue,因此我们用ROB编号来标记每一条指令(用于数据冲突时等情况)
多发射的例子
作业复盘
HW1
- 资源占比等价于所需的时间,可并行化程度意味着采取多核处理的时候,有多少的比例可以参与优化;
- 利用资源占比分配核数,应当向下取整,避免整体的核数超出总核数
- 计算整体加速比的时候,先分别计算对应的时间,然后利用并行前后的总时间来计算加速比
- 由此计算得出的总时间,可以用于重新分配所需的计算资源
HW2
功耗计算

ans:

注意分别计算静态功耗和访问功耗,前者需要先计算对应的时间
HW3
- B.5 涉及cache、AMAT和CPI的计算,可以参考作业的解答
其他没有什么问题
HW4
- GFLOP:以G为单位,执行的浮点数操作
其他没有什么问题
TODO
硬件原语部分
TODO:5.3ppt的18/40开始没有记录(学无余力)
- 标题: 计算机体系结构复习
- 作者: ffy
- 创建于 : 2025-06-21 19:03:24
- 更新于 : 2025-06-29 10:03:09
- 链接: https://ffy6511.github.io/2025/06/21/课程笔记/arch复习/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。


